Historian
HistorianOverview
About Configuration Hub
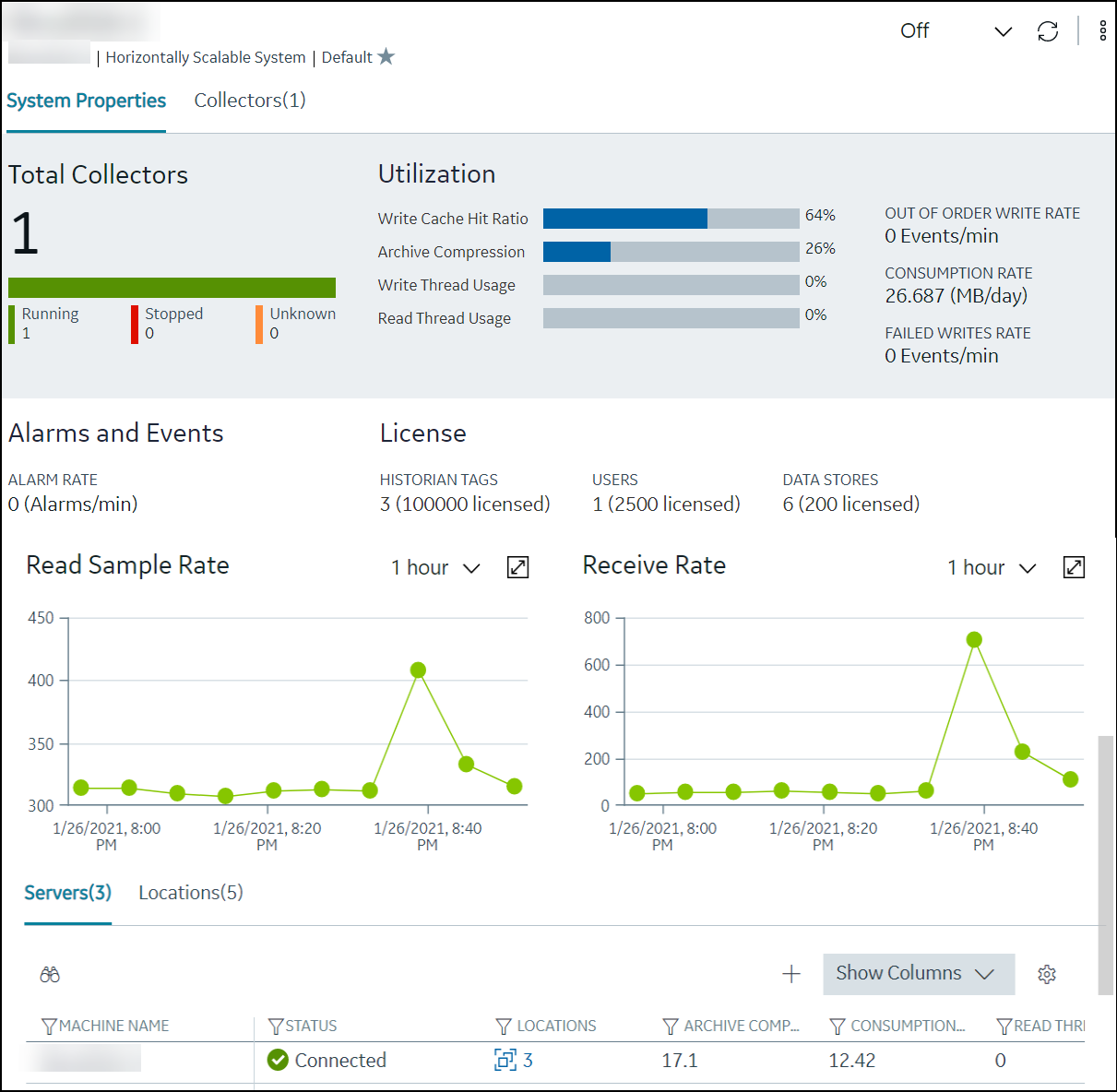
The Configuration Hub application allows you to manage the Historian systems and its components.
- A single application that enables you to manage multiple Historian systems: You can create and manage Historian systems using Configuration Hub. In addition, you can manage collectors, data stores, and tags.
- Horizontal scalability: You can increase the storage capacity of a Historian system by connecting multiple software entities so that they work as a single logical unit. This will improve the performance of the Historian system. The storage capacity depends on the number of Historian licenses that you have purchased.
- High availability: You can create mirror locations in a Historian system to achieve high availability of the server. If one of the servers is not available, you can retrieve data from the remaining servers in the mirror location.
- Ease of setting up: You can install all the collectors used in a Historian system easily by providing the required details with the help of the user-friendly interface.
- Stand-Alone: In a stand-alone Historian system, there is only one Historian server. This type of system is suitable for a small-scale Historian setup.
- Horizontally scalable: In a horizontally scalable Historian system, there are multiple Historian servers, all of which are connected to one another. This type of system is used to scale out the system horizontally. For example, if you have 5,00,000 tags in your Historian system, you can distribute them among the various servers to improve performance.
- Servers: A server is a machine on which Historian is installed. It contains a location and one or more data stores. A stand-alone Historian system contains only one server, whereas a horizontally scalable one contains multiple servers.
- Data stores: These are logical collections of tags used to store, organize, and manage tags according to your requirements. The primary use of data stores is segregating tags by data collection intervals. For example, you can put name plate or static tags (where the value rarely changes) in one data store, and put process tags in another data store. This can improve the query performance.
- Locations: These are virtual entities in which data stores are created.
They are used for storage. The following types of locations are used in a
horizontally scalable Historian system:
- Distributed location: This location is created automatically when you install a Historian mirror primary server, or when you install a Historian distributed/mirror node and add it to the primary server. You cannot modify or delete this location, or create another one.
- Mirror location: This location is used to replicate data collected in a data store. When you create a mirror location, you add one or more servers to the group, and then create the data stores whose data you want to replicate. For example, suppose you want to create a data store for collecting the data for 100 tags, for which you want high availability. In that case, you must create a mirror location, add two or more servers to the mirror location, and then create the data store. When you do so, the data retrieved in the data store is stored in all the servers in the mirror location. If one of the servers is down, you can retrieve the data from the other servers in the group.
- Tags: These are the parameters for which you want to store data (for example, temperature, pressure, torque).
- Collectors: These are the applications that collect data from a data source, and send it to Historian or another destination such as Predix Time Series or an Azure IoT hub.
- Data archiver: This is a service that indexes all the data by tag name and timestamp, and stores the result in an .iha file.
- Clients: These are applications that retrieve data from the archive files using the Historian API.
- If only one machine remains in a mirror location, you cannot remove it.
- You cannot add comments, enable the debug mode, pause data collection, resume data collection, modify, or delete an instance of offline collectors. In addition, you cannot compress network messages. You can, however, add or delete the collector instance using the Collector Manager utility at a command prompt.
- If you install Configuration Hub and the Web Admin console on the same machine, and use self-signed certificates for both of them, the
login page for Configuration Hub does not appear. To prevent this issue, disable
the domain security policies:
- Access the following URL: chrome://net-internals/#hsts
- In the Domain Security Policy section, in the Delete domain security policies field, enter the domain name for Configuration Hub, and then select Delete.
- Configuration Hub is not supported in a clustered Historian environment.
Access Configuration Hub
Before you begin
Procedure
-
Double-click the Configuration Hub icon on your desktop (
 ).
The Configuration Hub login page appears.
).
The Configuration Hub login page appears. -
Log in with your credentials.
Note: By default, the username is <host name>.admin, and the password is the value that you have entered in the Admin client secret field on the User Account and Authorization Service page during Web-based Clients installation.The Configuration Hub application appears, displaying the following sections:
- The Navigation section: Contains a list of
systems that you have added, along with the host name of each system. In
addition, the default system added during installation of Enterprise
Historian appears. In the Navigation section:
- A stand-alone system is indicated by
 .
. - A horizontally scalable system is indicated by
 .
. - A default system is indicated by
 .
.
- A stand-alone system is indicated by
- The main section: Contains the properties and collectors in the
selected system.
- The Details section: Contains the details of
the item selected in the main section. If you select a system, you can
view the description of the system, and add data stores and mirror
locations using the Details section.
- The Navigation section: Contains a list of
systems that you have added, along with the host name of each system. In
addition, the default system added during installation of Enterprise
Historian appears. In the Navigation section:
Configuration Hub Workflow
This topic provides the high-level steps in using Configuration Hub to set up a Historian system and use it.
- Install single-server Historian.
- Add a Historian system.
- Add one or more data stores.
- Add the collector instances that you want to use.
- Start the collectors.
- Specify the tags for which you want the collectors to collect data. You can do so using Historian Administrator or offline configuration.
- Install Historian primary server. When you do so, a distributed location is created for the primary server.
- Apply the Enterprise license to the primary server.
- Add a Historian system.
- Install Historian distributed server on each machine that you want to add to the system.
- Apply the Distributed license to all the distributed servers.
- Add the distributed servers to the system. When you do so, a distributed location is created automatically.
- If you want high availability, add a mirror location in the system.
- Add one or more data stores to each location in the system. If you want high availability for one or more data stores, add them to the mirror location.
- Add the collector instances that you want to use.
- Start the collectors.
- Specify the tags for which you want the collectors to collect data. You can do so using Historian Administrator or offline configuration.
After you perform these initial steps, data is collected and stored in the Historian servers. You can then retrieve and analyze the data.
Common Tasks in Configuration Hub
| Task | Procedure |
|---|---|
| Show or hide the Navigation or the Details section. |
|
| Search for an item in a table in the main section. |
|
| Filter items in a table in the main section. |
|
| Show or hide columns in the main section. Note: You cannot hide some of the columns (for example, the COLLECTOR NAME column). |
|
| Reorder columns. Note: You cannot reorder some of the columns. |
|
| Refresh a page. |
|
 .
. .
. .
. .
. .
.About Data Mirroring
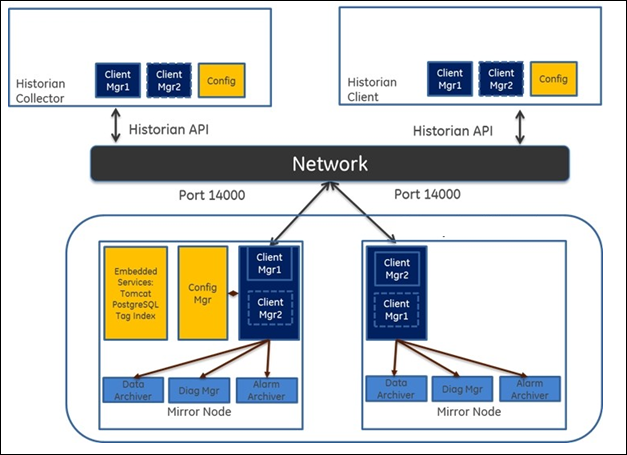
Historian provides mirroring of stored data on multiple nodes to provide high levels of data reliability. Data Mirroring also involves the simultaneous action of every insert, update and delete operations that occurs on any node. Data mirroring provides continuous data read and write functionality.
In a typical data mirroring scenario, one server acts as a primary server to which the clients connect. All communication goes through the Client Manager, and each Client Manager knows about the others. Mirrors must be set up in a single domain.
Mirror Node Setup