APM Family Data Loader
The APM Family Data Loader General Loading Strategy
This section describes any prerequisites to loading the data and the order in which the data will be loaded.
Before You Begin
- Determine Load Type: Single Family or Two Related Families.
The APM Family Data Loader supports loading records into a single family, or you can load records into one family and records into another family and link the two records together. The type of data that you want to load will determine the sample template with which you will start.
- Determine What Families and Relationships to Populate.
You can determine which families are available and how families are related in Family Management. To access Family Management:
Procedure
- Determine if you want to load data into a single family or into two families that are related to each other.
- Access a sample APM Family Data Loader source file based on the type of load determined in step 1.
- Determine what families and or relationships you want to populate using the APM Family Data Loader.
- Export the metadata that reflects the metadata definition for the family or families into which you want to load data.
- Populate the Configuration worksheet.
- Populate the column headers of the <Data> worksheet using the exported metadata.
- As needed, modify the worksheets to populate unit of measure to apply the correct unit of measure to any of the numeric fields.
- As needed, modify the worksheets to populate time zones to convert any date or time fields to the correct time zone.
About the APM Family Data Loader Workbook Layout and Use
This section provides a high-level overview and explanation of how the data loader workbook is constructed.
In order to import data using the APM Family Data Loader, APM provides an Excel workbook that must be used to perform the data load.
The following table lists the worksheets that are included in the APM Family.xlsx workbook.
| Worksheet | Description |
|---|---|
| Configuration | The Configuration worksheet is needed to describe the type of data that you will be loading and how that data should be handled during the data load. |
| <data> | Where you specify the actual data to be loaded. |
Each worksheet in the APM Data Loader workbook contains field values that can be mapped to the appropriate APM Family Data Loader family/field.
Configuration Worksheet
The Configuration worksheet tells the APM Family Data Loader what types of data are being loaded and how the data is to be loaded and is standard for all data loads regardless of the type of data that you are loading. The following table outlines the options that are valid or the values that are expected in each of the columns on the Configuration worksheet.
| Field Caption | Field ID | Data Type (Length) | Comments |
|---|---|---|---|
| Number of Rows to Chunk | OPTION_NUMBER_ROWS_TO_CHUNK | Character | Option to break-up or chunk data. |
| Load Data From Worksheet | LOAD_DATA_WORKSHEET | Boolean | Identifies if data from the corresponding worksheet identified in the Data Worksheet ID column will be loaded or not.
|
| Data Worksheet ID | DATA_WORKSHEET_ID | Character | This column contains the name of the <data> worksheet where the actual data is located. It needs to have the same name as the <data> worksheet in the data loader workbook. |
| Batch Size | BATCH_SIZE | Character | Modifying this field is required to determine the number of records processed in each batch. Enter the batch size you want, and the Data Loader will process that many records per batch. For example, if you want to use a batch size of 100, enter 100, and the data loader will process 100 records per batch. Note: The recommended batch size is 100. If the Batch Size column is removed from the source workbook, the data loader will default to a batch size of 100. In addition to processing the data in batches, the log file reports progress by batch. |
| Primary Family ID | PRIMARY_FAMILY_ID | Character | Depending on the type of data that you are working with, this will contain the Relationship Family ID or the Entity Family ID. You can also allow the data in source file to determine the Family ID by encapsulating the Field ID that contains the Family ID data in brackets (<>). For example, if in the <data> worksheet there is a column with an ID of PRIMARY_FAMILY_ID, where each row contains the corresponding Family ID, then in this column you should put the value of <PRIMARY_FAMILY_ID>. If the Family ID in the Meridium, Inc. metadata contains spaces, then you have to use this feature. |
| Primary Family Key Fields | PRIMARY_FAMILY_KEY_FIELDS | Character | This column contains the Field IDs associated with the Primary Family that are used to uniquely identify a record. If more than one field is to be used, then each Field ID needs to be separated by a | (Pipe) character. In the case where you are loading data into a relationship, if no keys fields exist or are used, use the <none> constant. If the Primary Action is ACTION_INSERTONLY, then no key fields need to be specified, so you can use the <none> constant. |
| Family Type | FAMILY_TYPE | Character | The value is this column should be Entity or Relationship depending on the type of data that is being loaded. |
| Predecessor Family ID | PRED_FAMILY_ID | Character | When the Family Type is Relationship, this column will contain the value of the Entity Family ID that is the predecessor in the relationship. Otherwise, it should contain the <none> constant. You can also use the data in each of the rows to determine the Predecessor Family ID. |
| Predecessor Family Key Fields | PRED_FAMILY_KEY_FIELDS | Character | This column contains the Field ID or IDs associated with the Predecessor Family that are used to uniquely identify the predecessor record. If more than one field is to be used, then each Field ID needs to be separated by a | (Pipe) character. If the Predecessor Action is ACTION_INSERTONLY, then no key fields need to be specified, so you can use the <none> constant. |
| Successor Family ID | SUCC_FAMILY_ID | Character | When the Family Type is Relationship, this column will contain the value of the Entity Family ID that is the successor in the relationship. Otherwise, it should contain the <none> constant. You can also use the data in each of the rows to determine the Successor Family ID. |
| Successor Family Key Fields | SUCC_FAMILY_KEY_FIELDS | Character | This column contains the Field ID or IDs associated with the Successor Family that are used to uniquely identify the successor record. If more than one field is to be used, then each Field ID needs to be separated by a | (Pipe) character. If the Successor Action is ACTION_INSERTONLY, then no key fields need to be specified, so you can use the <none> constant. |
| Primary Action | PRIMARY_ACTION | Character | The value in this column will determine the action that will be applied to the Primary Family records. If the Family Type is Entity, then the possible values are:
Deleting a record and purging a record will both delete the current record, the difference being that the purge action will delete the record and all of the links or relationships tied to that record. The delete action will simply attempt to delete the record, and if it is related to another record, the delete will fail. If The Family Type is Relationship, then the possible values are:
|
| Predecessor Action | PRED_ACTION | Character | The value in this column will determine the action that will be applied to the Predecessor Family records. The possible values are:
If The Family Type is Entity, then the values need to be
|
| Successor Action | SUCC_ACTION | Character | The value in this column will determine the action that will be applied to the Successor Family records. The possible values are:
If The Family Type is Entity, then the values need to be
|
| Insert with Null Values? | OPTION_INSERT_ON_NULL | Boolean | When setting field values on a new record, if a value coming across is NULL, the field values will be set to NULL if this option is set to True. |
| Update with Null Values? | OPTION_UPDATE_ON_NULL | Boolean | When setting field values on an existing record, if a value coming across is NULL, the field values will be set to NULL if this option is set to True. |
| Replace an Existing Link? | OPTION_REPLACE_EXISTING_LINK | Boolean | The Replace Existing Relationship option is used to determine how a relationship is to be maintained by its cardinality definition. For example, the relationship Location Contains Asset that is defined in the Configuration Manager. It has a cardinality defined as Zero or One to Zero or One, has a Location LP-2300, and contains the Asset P-2300. If, in the data load, you assign the Asset P-5000 to be contained in the Location LP-2300, and you have set the Replace Existing Link property to True, then the data loader will link P-5000 to LP-2300 and unlink P-2300 from LP-2300. This assumes that P-5000 is not currently linked to another location. The same is true for a relationship that is defined as Zero or One to Zero or Many, or Zero or Many to Zero or One. |
| Allow Change of Family? | OPTION_ALLOW_CHANGE_OF_FAMILY | Boolean | Allows the data loader to move an entity from one family to another. For example, this would allow an entity that is currently assigned to the Centrifugal Pump family to be moved to the Reciprocating Pump family. All relationships will be maintained as long as the family to which the entity is being moved allows the same relationships. Note: Because of the extra processing required, by selecting this option, the interface performance will decrease. |
Family Data Loader Option to Break-up or Chunk Data
When loading data using the Family Data Loader, the data is broken-up into batches, based on the Batch Size specified on the Configuration sheet. The batches of the rows of data are then loaded in parallel into APM. When loading rows of data in parallel, it is possible that multiple rows of data in the same sheet represent the same record, which will cause the same record to be loaded in different batches. This results in creation of duplicate records, if the record in question did not exist in APM at the time that the data load was initiated. So, if the Primary, Predecessor or Successor Action is Insert/Update this scenario could play out. To avoid duplicate records from being created, the Data Loader Framework groups together similar rows of data into the same batch. When working with records the number of rows is relatively small, but when considering links, the number of rows can grow considerably.
- Caption: Number of rows to be chunked together
- Name: OPTION_NUMBER_ROWS_TO_CHUNK
In the corresponding row for that column, specify the number of rows to be chunked together. Specifying a positive integer value >= 1000 will cause the Data Loader Framework to chunk the rows of data into the number of rows specified, if the value is <= 0 this indicates that data chunking is not to occur when loading data for that sheet. Once that chunk of data has been loaded, the next chunk of data will be loaded, and so forth until all the rows of data for that sheet have been loaded. Then processing will continue with the rows of data in the next sheet.
<Data> Worksheet
There is no preexisting format that must be adhered to on the <data> worksheet, because the Data Loader operates on a flexible framework. Field captions and ID are determined based on the data that you want to load.
Use the metadata exported from APM to construct the <data> worksheet, to populate the rows with the actual data that will be loaded.
Steps: Export Metadata
Get a copy of the metadata definitions for the family or families that you will be working with to load data.
- Login to APM.
- In the Applications menu, navigate to .
- At the top of the page, in the File Name box, enter a file name and in the File Type box, select Excel (.xlsx).
- In the Select metadata type box, select Families, Fields and Field Behaviors.
- Select the family or families that you want to export and move them to the Selected Items list.Tip: Be sure to order the families in the order in which you want the fields to appear in the export.
-
Select Start Export.
The metadata is exported, and can be used to populate the <data> worksheet.
- Save the metadata.
Export Metadata to Load Thickness Measurements
If you want to load Thickness Measurements into APM, because Thickness Measurements needs to be related to a Thickness Measurement Location, you must also export that family along with the Has Measurements relationship family.
- Log in to APM.
- In the Applications menu, navigate to .
- At the top of the page, in the File Name box, enter a file name (for example, TM Measurements Metadata).
- In the File Type box, select Excel (.xlsx).
- In the Select metadata type box, select Families, Fields, Fields Behaviors, and then select the following families:
- Thickness Measurement Location
- Thickness Measurement
- Has Measurements.
Tip: Export the families in this order. This is how the fields appear in the export file.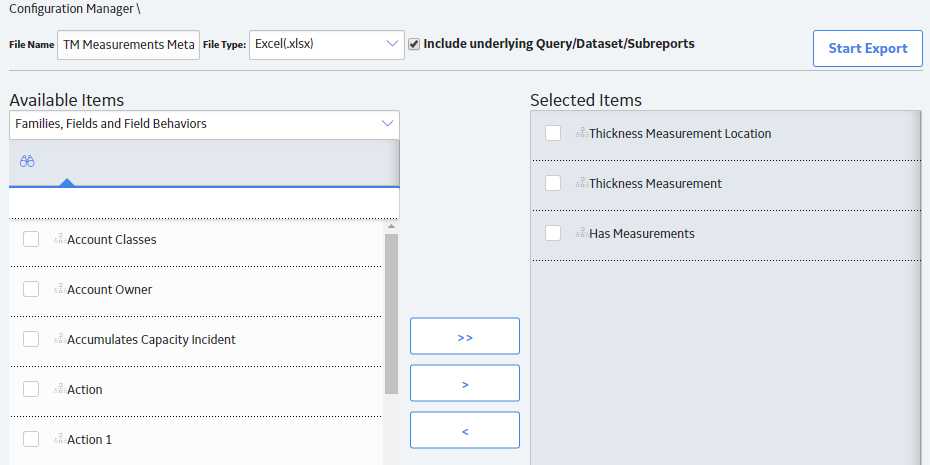
-
Select Start Export.
The metadata is exported, and can be used to populate the <data> worksheet.
-
Save the metadata.
This exported metadata, is used to build source file template.
Configure the Data Loader Source File to Use Units of Measure
Sometimes the data that is being loaded, is in a different unit of measure than the one associated with the corresponding field in APM. When this is the case, the APM Family Data Loader allows for you to specify the unit of measure that is tied to a specific row and column. This is done by copying the column to which the unit of measure is tied, and then adding the suffix |UOM to the end of the Column ID. Then, in the data, specify the unit of measure ID for the data being loaded. This unit of measure ID needs to be a valid unit of measure as defined in APM, and a valid conversion needs to be specified for the unit of measure specified and the field’s unit of measure. Please note that if a unit of measure is not specified, then it will use the field’s unit of measure, as defined in APM.
Configure the Data Loader Source File to use Time Zones
Sometimes date and time data that is being loaded was collected in a different time zone than the time zone associated with the current user. When this is the case, the APM Family Data Loader allows you to specify the time zone that is tied to a specific row and column. This is done by copying the column to which the time zone is tied, and then adding the suffix |TZ to the end of the Column ID. Then, in the data, specify the time zone for the data being loaded. A valid list of time zones can be found in the Microsoft .NET documentation. Please note that if a time zone is not specified, then it will use the time zone defined for the current user.
Example APM Family Workbooks
In addition to the APM Family Data Loader workbook, you can access an example workbook Foundation_APM_Data_Loader-Health Indicators and Readings example.xlsx. This example workbook illustrates how you can use the APM Family Data Loader to load records into a defined APM family and link records in one family to another. You can use the information in this example as a model to configure or define templates for loading data into any baseline or custom family.
The data loader in this example creates Health Indicator records in APM, links the Health Indicator records to Equipment records, and then links the Health Indicator records to Health Indicator Mapping records. Finally, the data loader loads Readings for one of the Health Indicators. In addition, the example spreadsheet includes how you can use a reference worksheet to store list values and other reference information that users can use when populating the data loader template with data.
Populate the Configuration Worksheet
The Configuration Worksheet tells the APM Family Data Loader what types of data are being loaded and how the data is to be loaded.Populate the HealthIndicators Worksheet
The HealthIndicators worksheet is populated with the actual Health Indicator records you want to load into APM.
Populate the HealthIndicatorsEquipment Worksheet
The HealthIndicatorsEquipment worksheet is populated with the key field values for the Equipment records to which the Health Indicators on the HealthIndicators worksheet will be linked once loaded into APM.
Populate the HealthIndicatorMappings Worksheet
The HealthIndicatorMappings worksheet is populated with the Health Indicator Mappings to load into APM.
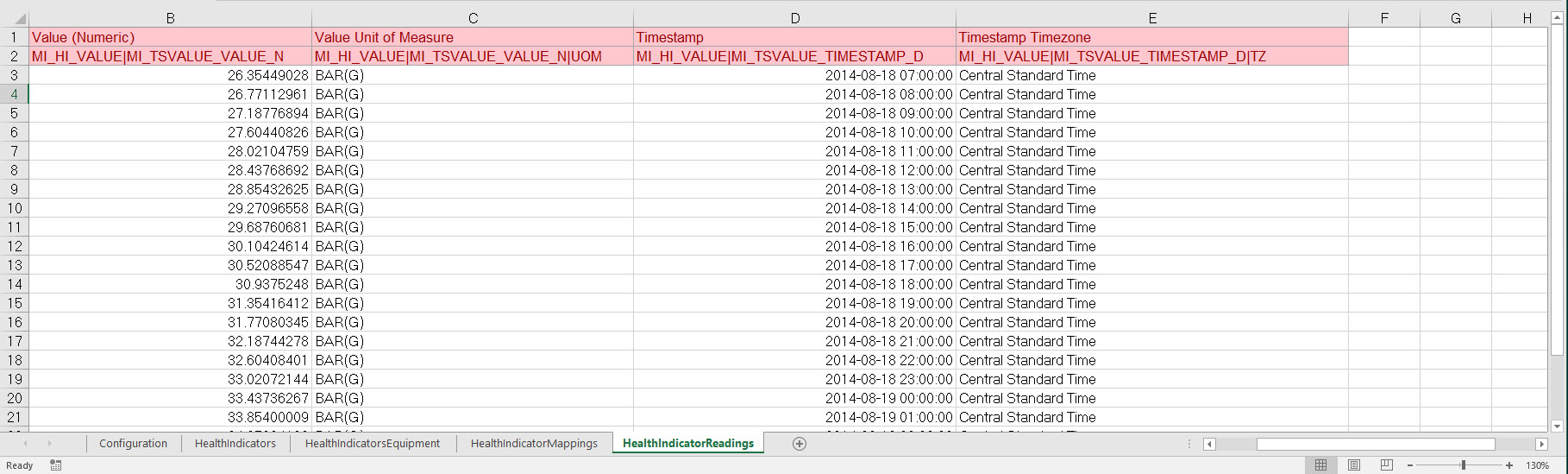
Populate the HealthIndicatorReadings Worksheet
The HealthIndicatorReadings worksheet is populated with the actual Health Indicators data you want to load into APM.
On this worksheet, Column C illustrates a feature of the APM Family Data Loader where the unit of measure for a given field can be indicated, so that it can be converted to the baseline unit of measure if needed. Assume, for example, that the MI_TSVALUE_VALUE_N field was defined in APM as being stored in PSIG, but the data in the spreadsheet was represented by BAR(G). As shown in the following image, you can add the UOM column to indicate to that the unit of measure for the source data is BAR(G). When this column is added, the APM Family Data Loader will convert the data from BAR(G) to PSIG (assuming that there is a unit of measure conversion defined for this in APM).
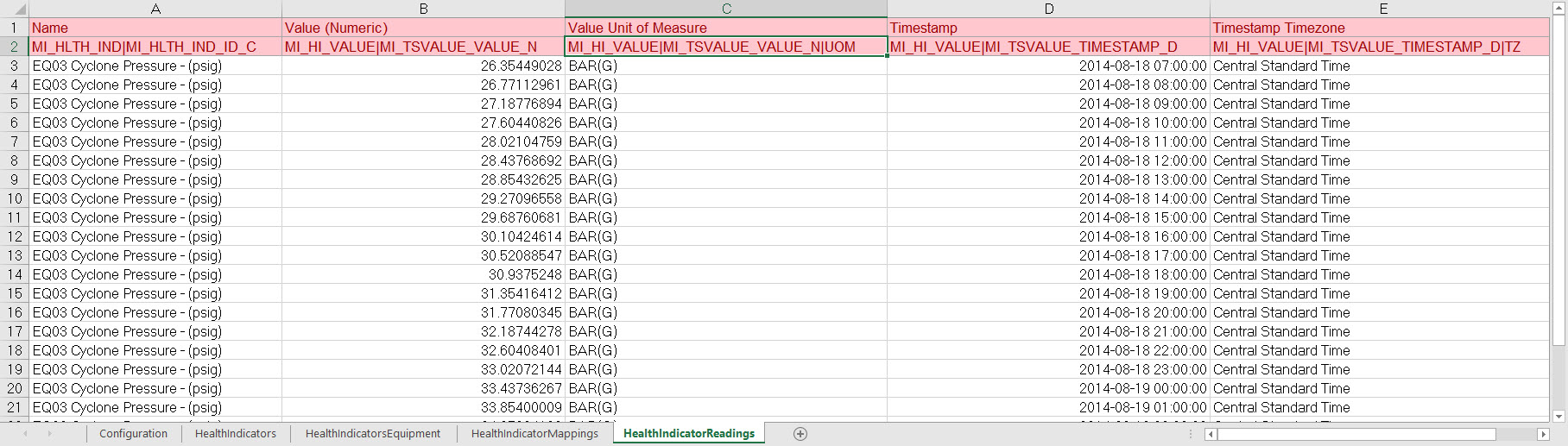
Additionally, column E of the HealthIndicatorReadings worksheet illustrates how time zones can be configured. Notice the appendage to the field name as shown in the following image. Adding a column where the Field ID is appended with a |TZ indicates the timezone of the source column data.