 Historian
HistorianStandard and High-Availability Configuration
Standard and High-Availability Configuration Options
You have wide flexibility in configuring the Historian system. Since Historian can support a fully distributed architecture, you can spread the data collection, server, administration, and client data retrieval functions across many different nodes in a network, or you can install all the components on a single computer.
Since the Historian API is the basic building block for connectivity, all Historian functions, including data collection, administration, and data retrieval, use the Historian API.
You can connect the Historian API to a local Historian server in the same manner as to a remote Historian server by simply providing the name of the server. This name must be the computer name or the IP address of the target Historian server, and the server must have a TCP/IP connectivity. If you use the computer name of the server rather than the IP address, the IP address must be available to the client through DNS, a WINS server, or through the local host table.
It is recommended that you install the Historian server on a central dedicated server. Next, install data collectors on each data source, and point them back to the central Historian server by specifying the appropriate server computer name. Install a separate data collector for each type of collection interface used in your system.
You can also have mirroring of stored data on multiple nodes to provide high levels of data reliability. Data mirroring also involves the simultaneous action of every insert, update, and delete operations that occur on any node.
You can install various types of collectors on a single computer, subject to constraints described in Install Collectors Using the Installer.
Standard Historian Architecture
Standard Historian offers unique capabilities and benefits for a sustainable competitive advantage:
- Built-in data collection
- Good read/write performance speed
- Enhanced data security
- Robust redundancy and high availability
Single Node Data Only System

Data Collection from SCADA Systems and other Programs
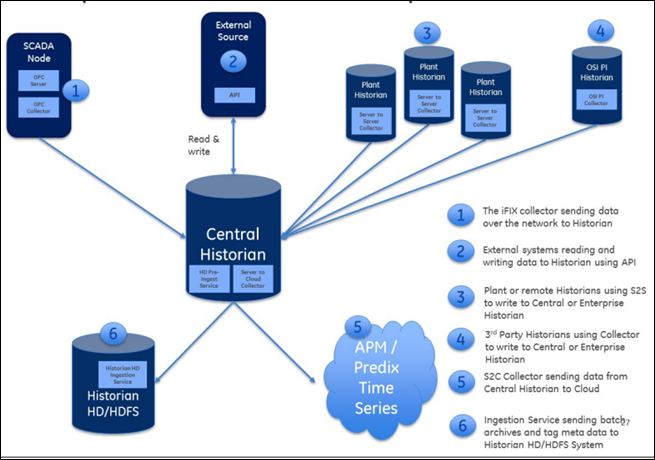
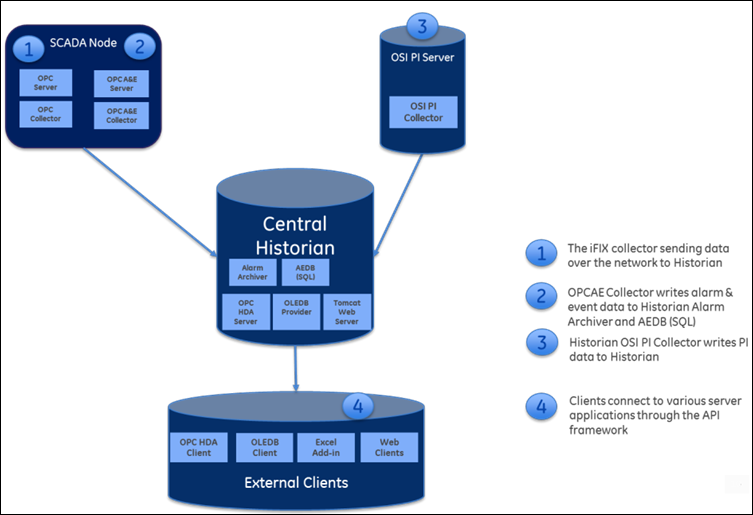
Integration with Client Programs
High-Availability Architecture

You can mirror stored data on multiple nodes to provide high levels of data reliability. Data mirroring involves the simultaneous action of every insert, update, and delete operation that occurs on any node. Historian allows you to maintain up to three mirrors, a primary and two additional mirrors.
Historian Data Mirroring
If you have purchased an Enterprise license for Historian and your license entitlement includes mirror nodes, you have the option of setting up to three mirrors (primary server + two mirrors).
Data mirroring provides continuous data read and write functionality. In a typical data mirroring scenario, one server acts as a primary server to which the clients connect.
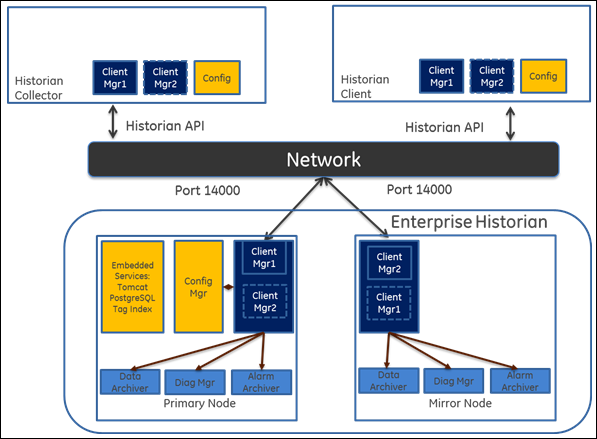
To create a mirror, you must add mirror nodes and establish a data mirroring session relationship between the server instances. All communication goes through Client Manager, and each Client Manager knows about the others.
Mirrors must be set up in a single domain.

Client Connections in Mirrored Environments
When a client (either a writing collector or reading client) connects to the Client Manager, it gathers information about each Client Manager, along with all archive, tag, and collector configuration information, from the Configuration Manager, and stores this information locally in its Windows Registry.
A relationship is then established between each remote client and a single Client Manager, which directs read and write requests across the other mirrors. If that relationship is broken, it will establish a new relationship with the next available Client Manager, which assumes the same responsibilities. This bond is maintained until that Client Manager is unavailable, and then the process of establishing a relationship with another Client Manager is repeated.
When more than one node is running, the Client Manager uses a "round robin" method between the good nodes to balance read loads. Each read request is handled by a node as a complete request.
Writes are sent independently but nearly simultaneously to any available data archiver so that the same tag shares a common GUID, name, timestamp, value, and quality as passed to it by the collector.
Read and Write Client with Mirroring
Historian in a Cluster Environment
- Verify that all the prerequisites are installed.
- Configure a failover cluster in the Windows server. See Installing Historian in a Cluster Environment.
- To use Historian Alarms and Events in a cluster environment, select the appropriate SQL Server for both the cluster nodes.




