 Historian
HistorianAdd and Configure a HAB Collector
About this task
Procedure
- Access Configuration Hub.
-
In the NAVIGATION section, under the Configuration Hub
plugin for Historian, select Collectors.
A list of collectors in the default system appears.
-
On the right, next to Settings in the main section, select
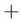 .
. The Add Collector Instance: <system name> window appears, displaying the Collector Selection section. The MACHINE NAME field contains a list of machines on which you have installed collectors.
The Add Collector Instance: <system name> window appears, displaying the Collector Selection section. The MACHINE NAME field contains a list of machines on which you have installed collectors. - In the MACHINE NAME field, select the machine in which you want to add a collector instance.
-
In the COLLECTOR TYPE field, select Hab
Collector, and then select Get Details.
The INSTALLATION DRIVE and DATA DIRECTORY fields are disabled and populated.
-
Select Next.
The Source Configuration section appears.
-
Enter values as described in the following table.
Field Description SERVER SITE Enter name that you want to assign to the site. A value is required and must be unique. It is used by Habitat to identify the collector instance. By default, this field is populated with a value in the following format: <Historian server name>HabSERVER 1 (under NODE 1) Enter the host name or IP address of the Habitat server in the primary site from which you want to collect data. This server acts as the primary/active server from which the collector receives data. A value is required. SERVER 1 (under NODE 2) Enter the host name or IP address of the Habitat server in the second/backup site from which you want to collect data. This server acts as a standby server in case server 1 under node 1 fails. A value is required. If you do not have a secondary/backup site, enter the same value as SERVER 1 under node 1. SERVER 2 (under NODE 1) Enter the host name or IP address of the Habitat server that you want to use as a standby server in the same site as server 1. This server acts as a standby server in case server 1 under node 2 fails. SERVER 2 (under NODE 2) Enter the host name or IP address of the Habitat server in the secondary/backup site from which you want to collect data. This server acts as a standby server in case server 2 under node 1 fails. For example, suppose Machine A and Machine B are in node AB, and Machine X and Machine Y are in node XY. Suppose you want to use Machine A as the primary server and the remaining machines as standby servers. In that case, enter values as follows:- SERVER 1 (under Node 1): Machine A
- SERVER 2 (under Node 1): Machine B
- SERVER 1 (under Node 2): Machine X
- SERVER 2 (under Node 2): Machine Y
SOCKET The socket number (port number) used by the Habitat Sampler application to connect. Each collector instance can connect to only one socket. The default value is 8040. RETRY The duration, in seconds, after which the collector tries to communicate with the site. The default value is 5 seconds. -
Select Next.
The Destination Configuration section appears. Under CHOOSE DESTINATION, the Historian Server option is selected by default. The other options are disabled because you cannot send data to a cloud destination using the HAB collector.
- If you want to connect to a remote Historian server, enter values in the USERNAME and PASSWORD fields.
-
Select Next.
The Collector Initiation section appears. By default, the COLLECTOR NAME field is populated with a value in the following format:
<Historian server name>_Hab -
If needed, modify the value in the COLLECTOR NAME field.
The value that you enter:
- Must be unique.
- Must not exceed 15 characters.
- Must not contain a space.
- Must not contain special characters except a hyphen, period, and an underscore.
-
In the SamplerID field, enter the user ID to connect to
Habitat Sampler.
By default, this field contains the Collector Name. You can first provide the Collector Name and update the Sample ID field as this filed will automatically takes the Collector Name.
-
In the RUNNING MODE field, select one of the following
options.
- Service - Local System Account: Select this option if you want to run the collector as a Windows service using the credentials of the local user (that is, the currently logged-in user). If you select this option, the USERNAME and PASSWORD fields are disabled. By default, this option is selected.
- Service Under Specific User Account: Select this
option if you want to run the collector as a Windows service using a
specific user account. If you select this option, you must enter values
in the USERNAME and
PASSWORD fields. If you have enabled the Enforce Strict Collector Authentication option in Historian Administrator, you must provide the credentials of a user who is added to at least one of the following security groups:
- iH Security Admins
- iH Collector Admins
- iH Tag Admins
-
Select Add.
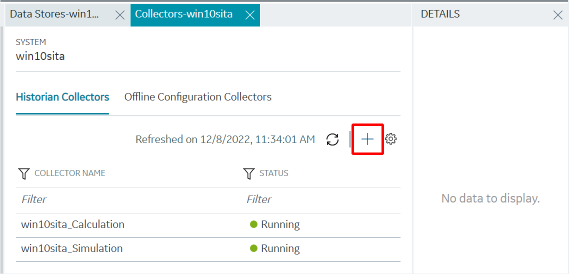
The collector instance is added. The fields specific to the collector appear in the DETAILS section.
-
Depending on whether you want to configure tags or alarms, select
 next to the
corresponding field under Collection Definitions.
next to the
corresponding field under Collection Definitions. The Data Collections or Alarm Collections section appears.
The Data Collections or Alarm Collections section appears. -
Select , and then enter
values in the available fields for data collection and/or alarm
collection. You can also copy a collection definition by
right-clicking it and selecting Duplicate.
-
Under Collector Specific Configuration, enter values as
described in the following table.
Field Description Auto Tag Sync If you enable this option, the collector creates tags automatically in Historian based on the key value. In addition, any tag changes in Habitat (such as adding, renaming, and deleting tags) will reflect automatically in Historian. No manual steps are required. If you disable this option, any tag changes in Habitat will be captured in the <collector name>_Tag_Unconfirmed.xml file. Only after you approve these changes, they are reflected in Historian.
Tag Deletion Type Specify whether deleted tags in Habitat that you have approved must be deleted or disabled for data collection in Historian. Enter one of the following values: - DISABLE_TAG (this is the default value)
- DELETE_TAG
- As needed, provide values in the remaining fields.
-
In the upper-left corner of the page, select Save.
 The changes to the collector instance are saved.
The changes to the collector instance are saved. - Start the collector.
What to do next
- Right-click the HAB collector instance that you have created, and then select Confirm Queued
Tags.
A list of tags that have been changed appears.
- Select the check boxes corresponding to the tags whose changes you want to
approve, and then select Confirm. You can filter the list
using the TAG TYPE field.
The tag changes are approved. The status of the tags is updated in the <collector_name>_tag.xml file (that is, the Confirmed parameter is set to true).