 Historian
HistorianHigh Availability
High availability of the Habitat server and the HAB collector provides uninterrupted data collection. You can configure a stand-by Habitat server and/or a second instance of the HAB collector to achieve high availability.
You can choose one of the following types of configuration:
- Single collector instance and single Habitat server: In this
configuration, a single HAB collector instance collects data from a single Habitat server.
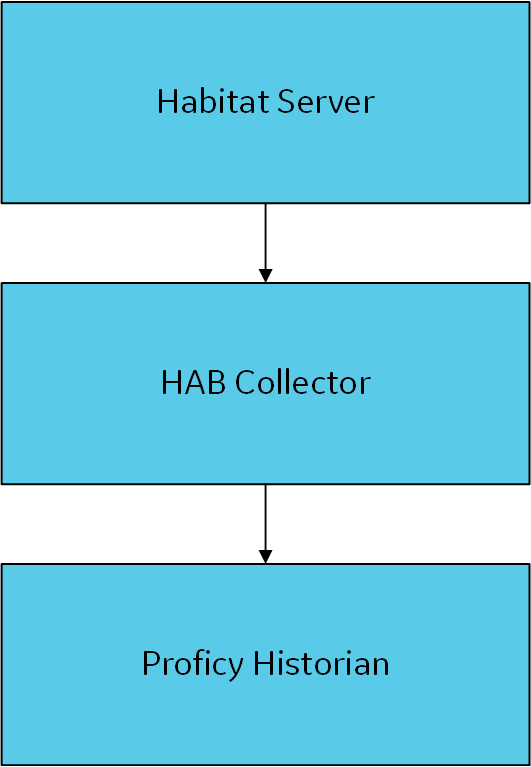 To set up this configuration, create a collector
instance, and provide
the details of the Habitat site in the configuration file of the
collector instance.
To set up this configuration, create a collector
instance, and provide
the details of the Habitat site in the configuration file of the
collector instance. - Redundant collector instances and single Habitat server: In this
configuration, a single Habitat server is connected to two collector
instances - one active and the other one standby. If the active collector
instance is not available, data is collected by the standby collector
instance.
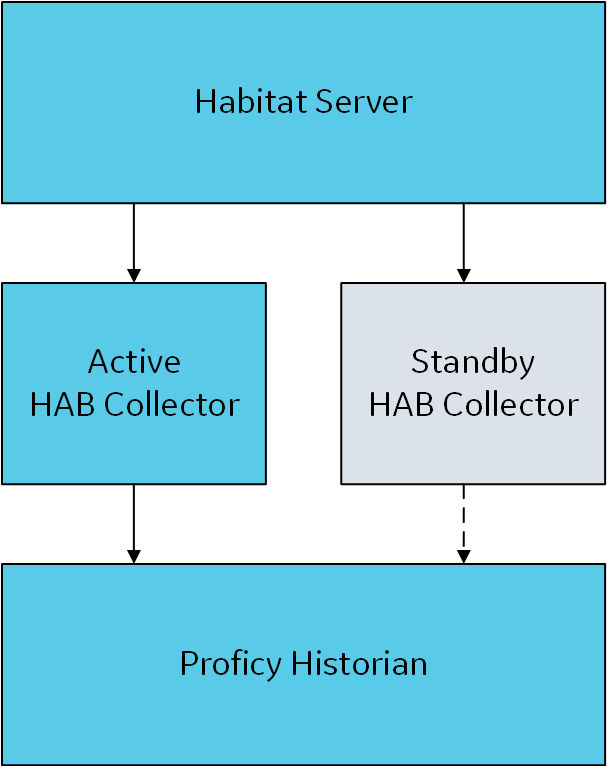 To set up this configuration, create two instances of the
collector, and provide and same site details for both of them.
To set up this configuration, create two instances of the
collector, and provide and same site details for both of them. - Single collector instance and redundant Habitat servers: In this
configuration, a single collector instance is connected to two Habitat
servers - one active and the other one is standby. If the active server is
down, the standby server accepts requests from the collector and sends
data.
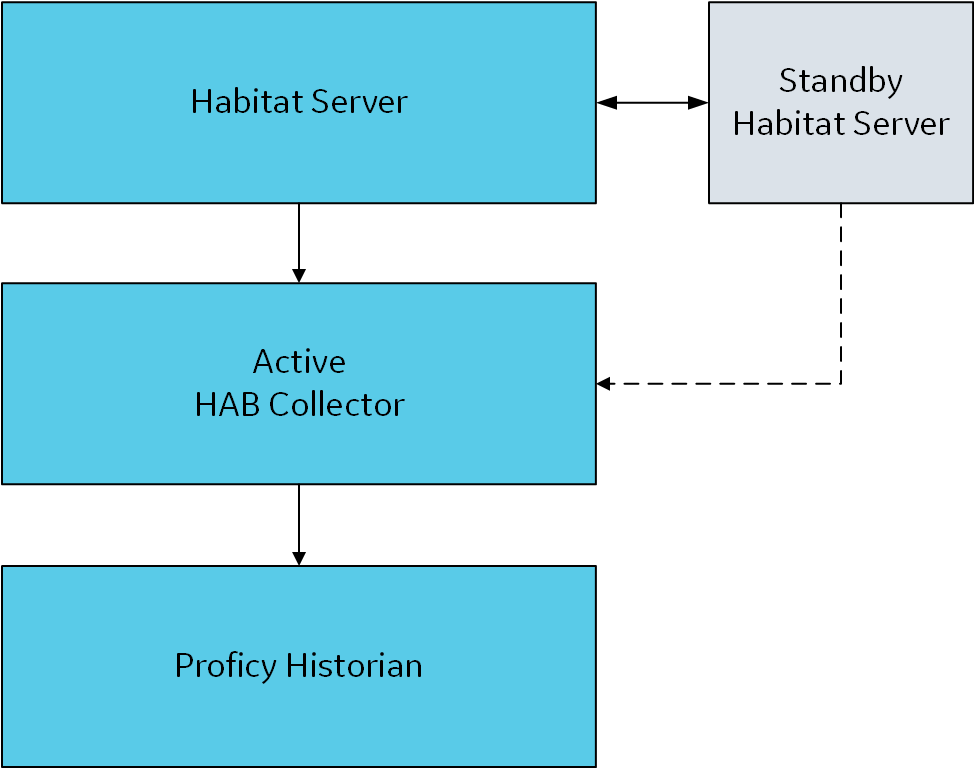 To set up this configuration, create a collector
instance, and provide
the details of the active and standby Habitat servers in the
Node1 and Node2 parameters respectively in the configuration file.
To set up this configuration, create a collector
instance, and provide
the details of the active and standby Habitat servers in the
Node1 and Node2 parameters respectively in the configuration file. - Redundant collector instances and redundant Habitat servers: In this
configuration, two collector instances are connected to two Habitat servers.
The active collector instance collects data from the active Habitat server.
If the active collect instance is not available, data is collected by the
standby collector instance. If the active Habitat server is down, the
standby server accepts requests from the active collector instance.
 To set up this configuration:
To set up this configuration:- Create two instances of the collector.
- For both the instances, provide the details of the active and standby Habitat servers in the Node1 and Node2 parameters respectively in the configuration file.
In addition to the high availability options provided by the collector and the Habitat server, you can set up data mirroring in the Historian server. For information, refer to About Data Mirroring. Or you can install Historian in a cluster environment.