Script Types
About Python Scripts
Scripts in GE Digital APM provide a way for you to utilize the Python programming language to create scripts for supervised machine learning or to create scripts that can receive data from inputs, make calculations, and then return one or more outputs.
Scripts can be used within Cognitive Analytics to expand the functionality of cognitions. Some baseline scripts are provided for your use, and you can create additional scripts. After you create and save a script, you can use either a Classifier or a Script node in Cognitive Analytics to pass values into the script and to receive calculated values out of the script.
When creating a new script, the following script types are available:
- Machine learning
- Fuzzy logic
- General
The following table summarizes the data requirements for each type of script.
|
Data Requirements |
Machine Learning ( training new) |
Machine Learning (testing existing) |
Fuzzy Logic |
General Script |
|
Set of observations |
X |
X |
X |
X |
|
Standard List |
X |
X |
X | |
|
Labeled data corresponding to the standard list (each observation requires a label) |
X |
|
About Machine Learning Scripts
Machine learning scripts use a Bayesian algorithm for data classification. Machine learning scripts also include training data to improve their ability to predict a target value. After you create and save a machine learning script, you can use the Classifier node in Cognitive Analytics to pass values into the script and to receive a target value prediction out of the script.
To function properly, machine learning scripts require the following:
- A reference to a standard list that represents standard values for the script's prediction.
- An input of a collection of words, such as a group of fields identified in a query, that are processed through the script's algorithm.
-
Training data.
When executed, a machine learning script:
- Concatenates all the input words into a single set and cleans the text.
- Classifies the data represented by the input words, and chooses one of the standard values in the standard list as the prediction.
- Returns the predicted classification along with a score for the prediction.
About Fuzzy Logic Scripts
Fuzzy logic scripts contain an algorithm that includes logic for exact string matching and fuzzy string matching. After you create and save a fuzzy logic script, you can use the Classifier node in Cognitive Analytics to pass values into the script and to receive a target value prediction out of the script.
To function properly, fuzzy logic scripts require the following:
- A reference to a standard list that represents standard values for the script's prediction.
- An input of a collection of words, such as a group of fields identified in a query, that are processed through the script's algorithm.
- References to standard lists for text cleaning.
When executed, a fuzzy logic script:
- Concatenates all the input words into a single set and cleans the text.
- Identifies exact matches from the standard list of standard values.
- Identifies fuzzy matches from the standard list of standard values.
If neither an exact nor a fuzzy match is found, a blank prediction is provided and a score of zero is returned.
If one match is found, the matched word is returned as the prediction along with the prediction's score.
If more than one match is found, the following criteria is applied:
- The matched word with the highest score is returned as the prediction along with the prediction's score.
- If there is a tie between matches with the highest score, the matched word with the highest weight per the standard list of standard values is returned as the prediction along with the prediction's score.
- If there is a tie between both the score and the weight of the matches, the first matched word in alphabetical order is returned as the prediction along with the prediction's score.
About General Scripts
General scripts provide a way for you to utilize the Python programming language to create scripts that can receive data from inputs, make calculations, and then return one or more outputs. General scripts can be as simple or as complex as you need them to be, depending on the data that you want the script to calculate.
General scripts can be used in a Cognitive Analytics cognition with a Script node. The parameters that you define in the script determine how the Script node in Cognitive Analytics will behave. Each single-value parameter that you specify as an input appears as a field on the Properties window for the Script node. You can then use standard cognition options to provide values to the parameters in the script. The output of a Script node is determined by the general script, which can produce an output to use as the value and an Output to use as the score of a predicted value, or a single-value output as calculated by the general script. The output of the general script determines what values subsequent nodes in the cognition can use for additional calculations or actions.
General Script Basic Principles
When working with general scripts within GE Digital APM, you must understand the basic principles described in this section.
Script Structure
A script used in GE Digital APM must have the following structure:
- The script must import any Python libraries. The following Python libraries are supported in GE Digital APM:
- chardet (2.2.1)
- fuzzywuzzy (0.10.0)
- nltk (3.2.1)
- numexpr (2.2.2)
- numpy (1.8.2)
- pandas (0.13.1)
- python-dateutil (2.0)
- python-Levenshtein (0.12.0)
- pytz (2012c)
- requests (2.2.1)
- scikit-learn (0.17.1)
- scipy (0.13.3)
- urllib3 (1.7.1)
- The script must have a
def main():function. - All functions used in the main script must be defined.
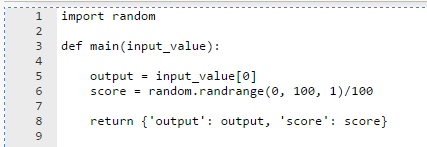
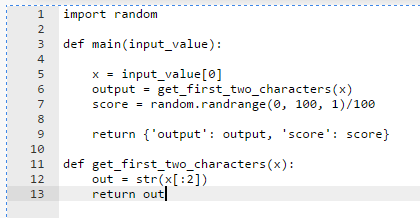
The following images show basic examples of the expected structure of a Python script.
Example 1
Example 2
Inputs
A script can have multiple inputs, which must be included in the def main(): function in the script definition. You can define single-value inputs, a list of inputs, or both.
When determining the best way to define the inputs to your script, consider these points:
- If you include a list of inputs, you cannot control the order in which the values in the list are processed by the script. Therefore, if you need to handle multiple values in a script separately, you should define multiple single-value inputs.
-
If you use a list of inputs, consider the following options to control the number of items in the input:
-
You can configure a script to use a set number of list inputs. If you do this, you must always select that many columns in the input data.
-
You can use a text cleanup library in your script. If you do this, the whole list will be concatenated and will return one string of values that you can use.
Tip:The following script excerpt shows how you could call a text cleanup library in your script:
from meridium.classifier.pipeline import TextCleanupPipelinetextCleanupPipeline = TextCleanupPipeline()def main(data):out = textCleanupPipeline.Clean(data[0])return {'out': out} -
You can write the logic in the script that checks the number of inputs.
-
-
Only single-value inputs appear on the Properties window for the Script node in Cognitive Analytics.
-
If you include both a list of inputs and single-value inputs, you must include the list of inputs before the single-value inputs in the
def main ():definition.
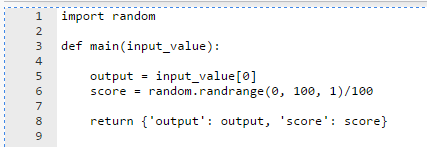
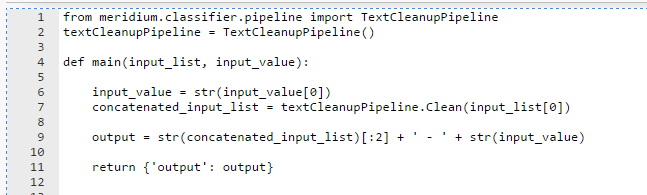
The following images show examples of the types of inputs you can define.
Single-Value Input
List Input

Both List and Single-Value Input
Outputs
A general script in GE Digital APM can have only two outputs:
- Value: This should be the value that the scripts predicts, and it will appear in the Prediction column when you test the script. Although a list can be used as an output, we recommend that you use only single-value data types.
- Score: This should be a calculation of the accuracy of the prediction, and it will appear in the Score column when you test the script. This output should use the data type Single Value - Numeric. This output is not required, but if you do not use it, the Score column will contain 0.0% for all results.
The output in the script must be returned as a dictionary in the format {‘id’:key, ‘id2’:key2 }, where each key corresponds to the parameter ID. For example: Return {‘output’:output, ‘score’: random.randrange(0, 100, 1)/100}
About Standard Lists
Standard lists are used by scripts to identify standard, valid values for predictions. Standard lists are also used to identify words that need to be removed or modified during a script's text cleaning process before they negatively impact predictions.
Standard Lists for Standard Values
Words in a standard list can be mapped to a standard value. Additionally, a weight can be added as a word's property to affect how likely it is to be selected in a fuzzy logic script's prediction.
The following image shows a portion of the failure mechanism standard list.
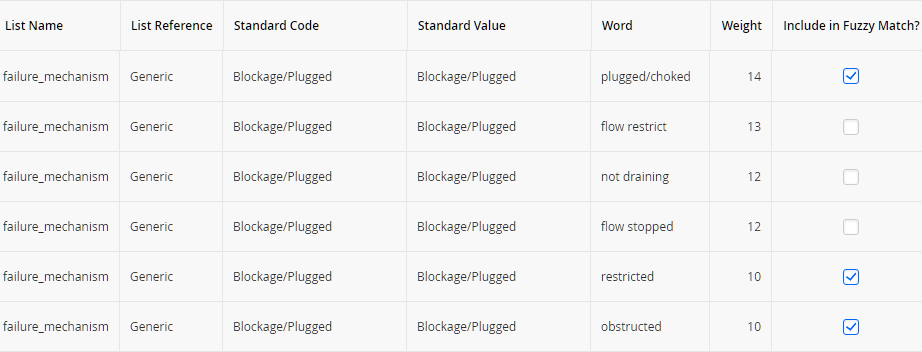
In the failure mechanism standard list, Blockage/Plugged in the Standard Value column is a standard value to which multiple words are mapped. If one of the mapped words in the Word column is found by a fuzzy logic script that uses the failure mechanism standard list, the script is likely to provide a predicted value of Blockage/Plugged.
Standard Lists for Text Cleaning
When fuzzy logic and machine learning scripts are executed, the text of the input words is cleaned. Some extraneous words are removed to eliminate noise, and some words are modified for consistency (e.g., the contraction didn't is modified to be did not).
The following image shows the stopwords standard list that is used to identify noise words to be removed during text cleaning.
About Script Score
The score of a prediction produced by a machine learning or fuzzy logic script represents the goodness of fit, in the statistical sense, for the specific prediction. When testing a script, scores are presented as a percentage between 0.0% and 100.0%. When passing the script score to a successor node in a Cognitive Analytics cognition, scores are presented as a numeric value between 0 and 1. Higher scores mean that the prediction, according to the script's logic, is more likely to be a correct prediction.
Example
The failureMechanism.py script is a fuzzy logic script used to identify the failure mechanism involved in a specific equipment failure.
The following table provides the text from sample work history events and the failureMechanism.py script's predictions for them and the corresponding scores.
| Event Short Description Text | failureMechanism.py Prediction | failureMechanism.py Prediction Score |
|---|---|---|
| REPLACE PUMP BEARINGS; OIL ANALYSIS INDICATES LARGE WEAR PARTICLES DENOTING SEVERE SLIDING AND BEARING WEAR | Wear | 100.0% |
| INSPECT IMPELLER FOR FOREIGN MATERIAL IT WAS PLUGGED OFF.. TORN DOWN, CLEANED AND REBUILT PUMP.. MOTOR WAS ALSO SENT OUT AND REBEARING | Blockage/Plugged | 85.0% |
| REPLACE IMPELLER; CHANGE TO AN ELEVEN INCH IMPELLER | Wear | 61.2% |
| HAS BAD SEAL. CHECK WITH OPER | Leakage | 59.7% |
About Script Prediction Improvement
If the predictions produced by a fuzzy logic or machine learning script do not meet the expected results, you can take action to improve the script's predictions. The method by which you improve a script's predictions depends upon the type of script.
Machine Learning Scripts: Adding Training Data
To improve a machine learning script's ability to predict target values, you can train the script by adding training data.
Training data includes relevant data for the specific machine learning script that enables the script to make consistent predictions. To train a machine learning script, you can create a query or dataset that includes relevant data and the corresponding correct target value. The fields of the relevant data provide text from which features can be produced. The script evaluates the specific features against the corresponding correct target value to help predict future target values.
The following table shows example fields that provide features and the target value of the isAFailure.py script.
| Fields that Provides Features | Target Value | |||
|---|---|---|---|---|
| Event Short Description | Event Long Description | Failure Mode Description | Priority Description | Breakdown Indicator |
The impact of the training data you add to a machine learning script depends upon the amount of training data you are adding in proportion to the existing amount of training data. For example, if you add 100 records of training data to a machine learning script that has 100,000 records of training data, the impact is minimal and the improvement may appear to be ineffective. However, if you add 50,000 records of training data to the existing 100,00 records, the impact will be significant and the improvement will be obvious.
If you are very confident in a training set of data, you can completely replace the existing training data with your training data set.
When developing training data, follow these important principles:
-
The training data should have a good distribution of labels (i.e., target values).
For example, if a machine learning script will predict a target value of either True or False, the training data should not have 95% of the records with True values and 5% of the records with False values, which would be called class imbalance. The training data should be more evenly spread to include a significant amount of samples of both True and False target values.
Tip: If you have imbalanced data (i.e., many more of one or two labels than the rest), you can improve the model predictions by ignoring that data and incrementally training several times, thereby oversampling the infrequent labels. -
The training data should be compatible with the input data used for predictions.
The training data should include similar words and phrases to those that are expected to be found in the input data. For example, if the training data only has words and phrases in English but the expected input data has words and phrases in Spanish, the training data is not compatible.
-
The initial set of training data should include a significant number of records to ensure that the machine learning script has a robust set of features.
Adding training data after the machine learning script has been trained initially does not add new features. If you are adding training data for the first time to a new machine learning script or you are removing the existing training data and replacing it with new training data, you should use a query or dataset with a significant number of records to create the initial set of training data. If you train a machine learning script on an initial training set with just a few records, the script will not produce accurate predictions.
Fuzzy Logic Scripts: Modifying the Standard List
Fuzzy logic scripts rely on a standard list of standard values in the Classifier Standard List family to produce predictions. If the predictions produced by a fuzzy logic script are invalid, you can modify the standard list of standard values that is referenced by the script in one of the following ways:
-
Add missing standard values. If the standard list does not contain a necessary standard value, it is impossible for the fuzzy logic script to use that value as a prediction. You can use Record Manager to add standard values, and their mapped words, to a standard list.
-
Add or modify mapped words to an existing standard value. If the standard value exists in the standard list, verify that the mapped words match words that are used in your data. If they do not match, you can use Record Manager to add or modify the mapped words for a specific standard value.
-
Modify the weight of mapped words. If your standard list contains both the correct standard values and mapped words that match your data but the prediction is consistently the wrong target value, you can use Record Manager to increase or decrease the weight of a mapped word. When the fuzzy logic script processes the input data, it creates scores for potential matches. In the case of a tie score, the script will select the word with the higher weight.