 Historian
HistorianStorage
Archive Compression
Archive Compression Overview
The Data Archiver performs archive compression procedures to conserve disk storage space. Archive compression can be used on tags populated by any method (collector, migration, File collector, SDK programs, Excel, etc.)
Archive compression is a tag property. Archive compression can be enabled or disabled on different tags and can have different deadbands.
Archive compression applies to numeric data types (scaled, float, double float, integer and double integer). It does not apply to string or blob data types. Archive compression is useful only for analog values, not digital values.
Archive compression can result in fewer raw samples stored to disk than were sent by collector.
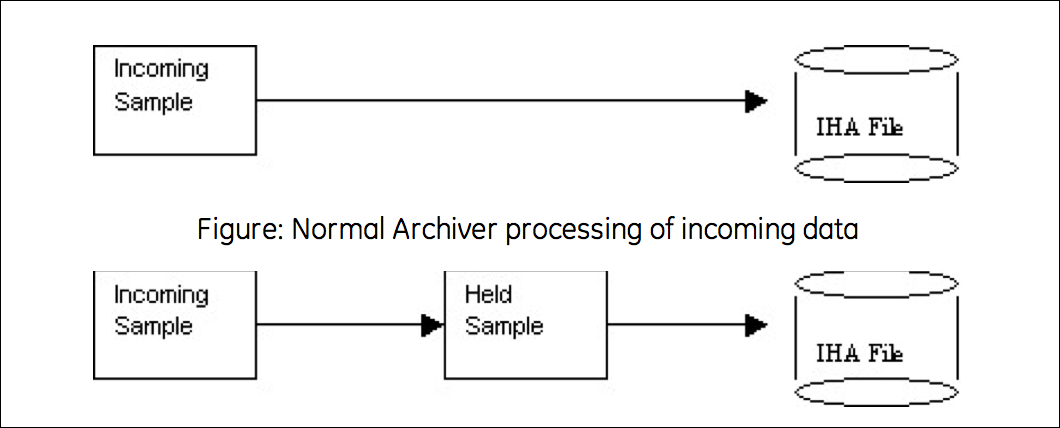
Archive Compression uses a held sample. This is a sample held in memory but not yet written to disk. The incoming sample always becomes the held sample. When an incoming sample is received, the currently- held sample is either written to disk or discarded. If the currently-held sample is always sent to disk, no compression occurs. If the currently-held sample is discarded, nothing is written to disk and storage space is conserved.
In other words, collector compression occurs when the collected incoming value is discarded. Archive compression occurs when the currently-held value is discarded.
Held samples are written to disk when archive compression is disabled or the archiver is shut down.
Archive Compression Logic
IF the incoming sample data quality = held sample data quality
IF the new point is a bad
Toss the value to avoid repeated bads. Do we toss new bad or old bad?
ELSE
Decide if the new value exceeds the archive compression deadband/
ELSE//
data quality is changed, flush held to disk
IF we have exceeded deadband or changed quality
// Store the old held sample in the archive
// Set up new deadband threshold using incoming value and value written to disk.
// Make the incoming value the held valueExample: Change of data quality
The effect of archive compression is demonstrated in the following examples.
- A change in data quality causes held samples to be stored.
- Held samples are returned only in a current value sampling mode query.
- Restarting the archiver causes the held sample to be flushed to disk.
| Time | Value | Quality |
|---|---|---|
| t) | 2 | Good |
| t1 | 2 | Bad |
| t2 | 2 | Good |
The following SQL query lets you see which data values were stored:
Select * from ihRawData where samplingmode=rawbytime and tagname =
t20.ai-1.f_cv and timestamp > today
Notice that the value at t2 does not show up in a RawByTime query because it is a held sample. The held sample would appear in a current value query, but not in any other sampling mode:
select * from ihRawData where samplingmode=CurrentValue and tagname =
t20.ai-1.f_cv
The points should accurately reflect the true time period for which the data quality was bad.
Shutting down and restarting the archiver forces it to write the held sample. Running the same SQL query would show that all 3 samples would be stored due to the change in data quality.
Archive Compression of Straight Line
| Time | Value | Quality |
|---|---|---|
| t0 | 2 | Good |
| t0+5 | 2 | Bad |
| t0+10 | 2 | Good |
| t0+15 | 2 | Good |
| t0+20 | 2 | Good |
Shut down and restart the archiver, then perform the following SQL query:
select * from ihRawData where samplingmode=rawbytime and tagname =
t20.ai-1.f_cv and timestamp > today
Only t0 and t0+20 were stored. T0 is the first point and T0+20 is the held sample written to disk on archiver shutdown, even though no deadband was exceeded.
Bad Data
| Time | Value | Quality |
|---|---|---|
| t0 | 2 | Good |
| t0+5 | 2 | Bad |
| t0+10 | 2 | Bad |
| t0+15 | 2 | Bad |
| t0+20 | 2 | Good |
| t0+25 | 3 | Good |
- The t0+5 value is stored because of the change in data quality.
- The t0+10 value is not stored because repeated bad values are not stored.
- The t0+15 value is stored when the t0+20 comes in because of a change of quality.
Disabling Archive Compression for a Tag
| Time | Value | Quality |
|---|---|---|
| t0 | 2 | Good |
| t0+5 | 10 | Good |
| t0+10 | 99 | Good |
| t0+15 | Archive compression disabled | |
- The t0 value is stored because it is the first sample.
- The t0+5 is stored when the t0+10 comes in.
- The t0+10 is stored when archive compression is disabled for the tag.
Archive Compression of Good Data
This example demonstrates that the held value is written to disk when the deadband is exceeded.
In this case, we have an upward ramping line. Assume a large archive compression deadband, such as 75% on a 0 to 100 EGU span.
| Time | Value | Quality |
|---|---|---|
| t0 | 2 | Good |
| t0+5 | 10 | Good |
| t0+10 | 10 | Good |
| t0+15 | 10 | Good |
| t0+20 | 99 | Good |
Shut down and restart the archiver, then perform the following SQL query:
select * from ihRawData where samplingmode=rawbytime and tagname =
t20.ai-1.f_cv and timestamp > today
Because of archive compression, the t0+5 and t0+10 values are not stored. The t0+15 value is stored when the t0+20 arrives. The t0+20 value would not be stored until a future sample arrives, no matter how long that takes.
Determining Whether Held Values are Written During Archive Compression
When archive compression is enabled for a tag, its current value is held in memory and not immediately written to disk. When a new value is received, the actual value of the tag is compared to the expected value to determine whether or not the held value should be written to disk. If the values are sufficiently different, the held value is written. This is sometimes described as "exceeding archive compression".
Archive compression uses a deadband on the slope of the line connecting the data points, not the value or time stamp of the points themselves. The archive compression algorithm calculates out the next expected value based on this slope, applies a deadband value, and checks whether the new value exceeds that deadband.
The "expected" value is what the value would be if the line continued with the same slope. A deadband value is an allowable deviation. If the new value is within the range of the expected value, plus or minus the deadband, it does not exceed archive compression and the current held value is not written to disk. (To be precise, the deadband is centered on the expected value, so that the actual range is plus or minus half of the deadband.)
Exceeding Archive Compression
EGUs are 0 to 200000 for a simulation tag.
Enter 2% Archive compression. This displays as 4,000 EGU units in the administration UI.
When a sample arrives, the archiver calculates the next expected value based on the slope and time since the last value was written. Let's say that the expected value is 17,000.
The deadband of 4,000 is centered, so the archiver adds and subtracts 2,000 from the expected value. Thus, the actual value must be from 15,000 to 19,000 inclusive for it to be ignored by the compression algorithm.
In other words, the actual value must be less than 15,000 or greater than 19,000 for it to exceed compression and for the held value to be written.
Determining Expected Value
The Archive Compression algorithm calculates the expected value from the slope, time, and offset (a combination of previous values and its timestamp):
ExpectedValue = m_CompSlope * Time + m_CompOffset;
Where
m_CompSlope = deltaValue / deltaT
m_CompOffset = lastValue - (m_CompSlope * LastTimeSecs)Determining Expected Value
Values arriving into the archiver for tag1 are
| Time | Value |
|---|---|
| t0 | 2 |
| t0+5 | 10 |
| t0+10 | 20 |
m_CompSlope = deltaValue / deltaTime m_CompSlope = (20-10) / 5
m_CompSlope = 2
m_CompOffset = lastValue - (m_CompSlope * LastTimeSecs)
m_CompOffset = 20 - (2 * 10)
m_CompOffset = 0
ExpectedValue = m_CompSlope * Time + m_CompOffset;
ExpectedValue = 2 * 15 + 0;
ExpectedValue = 30The expected value at t0+15 is 30.
Archive Compression of a Ramping Tag
An iFIX tag is associated with an RA register. This value ramps up to 100 then drops immediately to 0.
Assume a 5-second poll time in Historian. How much archive compression can be performed to still "store" the same information?
11-Mar-2003 19:31:40.000 0.17 Good NonSpecific
11-Mar-2003 19:32:35.000 90.17 Good NonSpecific
11-Mar-2003 19:32:40.000 0.17 Good NonSpecific
11-Mar-2003 19:33:35.000 91.83 Good NonSpecific
11-Mar-2003 19:33:40.000 0.17 Good NonSpecific An archive compression of 0% logs every incoming sample. Even on a perfectly ramping signal with no deviations, 0% compression conserves no storage space and essentially disables archive compression.
Archive Compression of a Drifting Tag
A drifting tag is one that ramps up, but for which the value barely falls within the deadband each time. Even though a new held sample is created and the current one discarded, the slope is not updated unless the current slope exceeded. With a properly chosen deadband value, this is irrelevant: by specifying a certain deadband, the user is saying that the process is tolerant of changes within that deadband value and that they do not need to be logged.Archive Compression of a Filling Tank
In the case of a filling tank, the value (representing the fill level) ramps up, then stops. In this case, the system also uses collector compression, so when the value stops ramping, no more data is sent to the archiver. At some point in the future, the value will begin increasing again.
As long as nothing is sent to the archiver, no raw samples are stored. During this flat time (or plateau), it will appear flat in an interpolated retrieval because the last point is stretched. This illustrates that you should use interpolated retrieval methods on archived compressed data.
How Archive Compression Timeout Works
The Archive Compression Timeout value describes a period of time at which the held value is written to disk. If a value is held for a period of time that exceeds the timeout period, the next data point is considered to exceed the deadband value, regardless of the actual data received or the calculated slope.
After the value is written due to an archive compression timeout period, the timeout timer is reset and compression continues as normal.
Archive De-fragmentation - An Overview
What is De-fragmentation? Having an IHA file with contiguous data values for a particular tag is called Archive De-fragmentation.
An Historian IHA (Historian Data Archive) file could contain data values for multiple tags and data written for a particular tag may not be in continuous blocks. This means data values in IHA files are fragmented.
Archive De-fragmentation improves the performance of reading and processing of archive data dramatically.
- An archive can be de-fragmented, when it is not active.
- A command line based tool can be used to run on any existing archive as needed.
- De-fragmentation can be done on all versions of archives, and the resulting archive will be the latest version.
- The de-fragmentation must be started manually.
De-fragmenting an existing archive
About this task
To de-fragment an archive using the tool:
Procedure
About Storing Future Data
You can store future data in Historian. This future data is the predicted data, which has a future timestamp. You can use this data to perform a predictive or forecast analysis, and revise the forecasting algorithms as needed.
The data is stored in the Historian Archiver. You can use it to analyse both the historical data and future data (for example, using trend charts), and take necessary actions. This allows you to refine the way the data to be stored in Historian is received and processed.
You can store future data related to all the data types used in Historian. You can store future data for all the tags associated with a data store.
- The OPC DA collector
- The OPCUA DA collector
- The OPCHDA collector
To use this feature, you must enable the storage of future data. You can do this using sample programs or Command Line.
You can then retrieve and/or extract this data using any of the available options such as Historian Administrator, Rest APIs, Excel Add-In, and the Historian Interactive SQL application (ihsql.exe).
- You can enable the future data storage only for a data store.
- You can collect future data only using the OPC Data Access, OPCUA Data Access, and OPC HDA collectors. You cannot collect future data using Calculation collectors such as Server-to-Server, Server-to-Distributor, and Calculation.
- When you select the Last 10 Values option for a tag, the results include the last ten values till the current date and time; the results do not include future data. If you want to view future data, you can filter the data based on the start and end dates.
- Future data is stored till 19 January, 2038.Note: You can store future data beyond the license expiry date of Historian. For example, even if the license expires by May 31, 2022, you can store future data that is predicted till 19 January, 2038. However, after the license expires, you cannot use this feature.
- For a tag for which you want to store future data, do not store past data.
- As this feature can lead to out-of-order data, use this feature carefully to avoid load on the server. For example, store future data in the chronological order of time.
- Data recalculation does not work for future data.
Suppose you have enabled the storage of future data for a data store named FDataStore.
Suppose the current time is 9.00 am, April 13, 2020. And, future data is stored from 11.00 am onwards, and a size-based archive is created to store the data.
Data can be stored in the archive file only from 11.00 am onwards.
Scenario 1: The timestamp of the data is in the past. For example: 11.00 am, April 12, 2020. A new archive file will be created to store this data. Therefore, to reduce load on the server, we strongly recommend that you store future data in the chronological order of time.
Scenario 2: The timestamp of the data is beyond the outside-active-hours of the archive file. For example: 11.00 am, December 12, 2020. Suppose the current archive file is active only for today. Data will not be stored in the archive file because the timestamp of the data falls beyond the outside-active-hours value of the archive file. To avoid this issue, a new archive file must be created in such scenarios. To do so, you must enable offline archive creation.
Scenario 3: The timestamp of the data is much further in the future. For example: 11.00 am, April 12, 2025. The current archive file may be used to store the data for this timestamp as well. This results in an optimum usage of the archive file instead of creating multiple archive files.
Enable Storing Future Data Using Command Line
Before you begin
About this task
Procedure
- Stop the Historian DataArchiver service.
- Open Command Prompt with elevated privileges or administrator privileges.
- Navigate to the folder in which the ihDataArchiver_x64.exe file is located. By default, it is C:\Program Files\Proficy\Proficy Historian\x64\Server.
-
Run the following command:
ihDataArchiver_x64 OPTION.<data store name> ihArchiverAllowFutureDataWrites 1 -
Run the following command:
ihDataArchiver_x64 OPTION.<data store name> ihArchiveActiveHours <number of active hours> - Start the Historian DataArchiver service.
Enable Storage of Future Data
Before you begin
About this task
Procedure
Results
Sample Program to Enable Future Data
Using C++
ihArchiverAllowFutureDataWrites option using C++:void SetFutureDataWriteOptions(void)
{
ihChar enable[50];
printf("\n\n Please enter 1/0 for enable/disable future data write per data store: ");
_getws(enable);
ihChar dataStoreName[50];
printf("\n\n Please enter data store name to enable future data writes ");
_getws(dataStoreName);
ihAPIStatus Status;
ihOptionEx option;
option.Option = ihArchiverAllowFutureDataWrites;
option.DataStoreName = dataStoreName;
Status = ihArchiveSetOption(SrvHdl, &option,enable);
}
void GetFutureDataWriteOptions()
{
ihChar dataStoreName[50];
printf("\n\n Please enter the name of the data store Future Data write Option: ");
_getws(dataStoreName);
ihAPIStatus Status;
ihChar *Value;
ihOptionEx temp;
temp.Option = ihArchiverAllowFutureDataWrites;
temp.DataStoreName = dataStoreName;
Status = ihArchiveGetOption(SrvHdl,&temp,&Value);
printf("Archive Future Data Write Option ihArchiverAllowFutureDataWrites value is - [%ls] for the data store [%ls]\n", (Value ? Value : L"NULL"), dataStoreName);
Pause();
}
Using C#
ihArchiverAllowFutureDataWrites option using C#:static void Main(string[] args)
{
string swtValue = "0";
string dsName = "";
ConsoleKeyInfo kInfo;
connection = ClientConnect.NewConnection;
do
{
Console.WriteLine("1 Set/Enable Data Store Create Offline Archives Option Value");
Console.WriteLine("2 Set/Enable Data Store Allow Future Data Writes Option Value");
Console.WriteLine("3 Get Data Store Create Offline Archives Option Value");
Console.WriteLine("4 Get Data Store Allow Future Data Writes Option Value");
Console.WriteLine("Enter Option Value");
swtValue = Console.ReadLine();
switch (swtValue)
{
case "1":
Console.WriteLine("Enter Data Store Name");
dsName = Console.ReadLine();
connection.IServer.SetOption(HistorianOption.ServerCreateOfflineArchives, "1", dsName);
Console.WriteLine("Option value set to " + connection.IServer.GetOption(HistorianOption.ServerCreateOfflineArchives, dsName));
Console.ReadKey();
break;
case "2":
Console.WriteLine("Enter Data Store Name");
dsName = Console.ReadLine();
connection.IServer.SetOption(HistorianOption.ArchiverAllowFutureDataWrites, "1", dsName);
Console.WriteLine("Option value set to " + connection.IServer.GetOption(HistorianOption.ArchiverAllowFutureDataWrites, dsName));
Console.ReadKey();
break;
case "3":
Console.WriteLine("Enter Data Store Name");
dsName = Console.ReadLine();
Console.WriteLine("Option value is: " + connection.IServer.GetOption(HistorianOption.ServerCreateOfflineArchives, dsName));
Console.ReadKey();
break;
case "4":
Console.WriteLine("Enter Data Store Name");
dsName = Console.ReadLine();
Console.WriteLine("Option value is: " + connection.IServer.GetOption(HistorianOption.ArchiverAllowFutureDataWrites, dsName));
Console.ReadKey();
break;
default:
Console.WriteLine("Please enter valid number");
Console.ReadKey();
break;
}
Console.WriteLine("Please Enter X to exit");
kInfo = Console.ReadKey();
} while (kInfo.Key != ConsoleKey.X);
}
}
Enable Offline Archive Creation
About this task
Procedure
- Stop the Historian DataArchiver service.
- Open Command Prompt with elevated privileges or administrator privileges.
- Navigate to the folder in which the ihDataArchiver_x64.exe file is located. By default, it is C:\Program Files\Proficy\Proficy Historian\x64\Server.
-
To enable the
ihArchiveCreateOfflineArchiveoption for a data store, run the following command:ihDataArchiver_x64 OPTION.<data store name> ihArchiveCreateOfflineArchive 1 -
To enable the ihArchiverAllowFutureDataWrites option:
-
Run the following command:
ihDataArchiver_x64 OPTION.<data store name> ihArchiverAllowFutureDataWrites 1 -
Set the
Read only After(Hrs)property ::::[specify value in number of hours)]ihDataArchiver_x64 OPTION.<data store name> ihArchiveActiveHours <number of active hours>.
-
Run the following command:
- Start the Historian DataArchiver service.




