Understanding the Interface
Understand the Historian Interface
| Number | Item | Description |
|---|---|---|
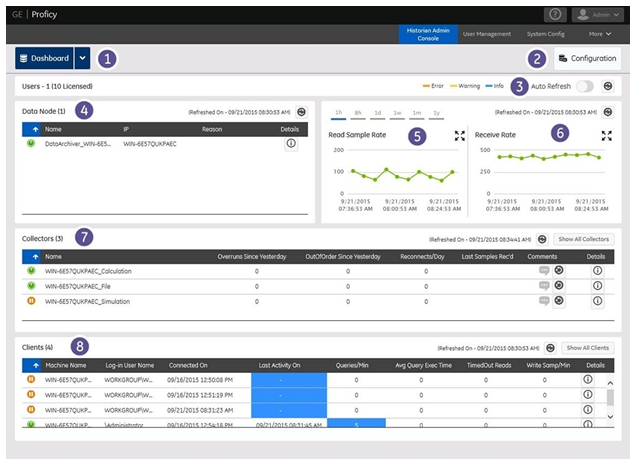
| 1 | Dashboard | This link at the top left of the screen opens the Historian Dashboard screen the one that you are currently viewing, which displays the overall picture of the system health. |
| 2 | Configuration | This link opens the Configuration panel. From there, you can view and modify the details of Collectors, Clients Services, Data Stores, Tags and Active Jobs. For more information, refer to the Configuration Panel topic. |
| 3 | Auto / Manual Refresh | If Auto Refresh is ON, then the screen is refreshed automatically. If Auto Refresh is OFF, then you can manually refresh the screen or the individual section of the dashboard by clicking the icon. |
| 4 | Data Node | This panel displays the basic information of the nodes (Primary Node & Mirror Nodes) currently available. To view the details of a particular node, click the Details button of the node. The Data Node screen appears. |
| 5 | Read Sample Rate | This panel gives you the trend of the average read sample rate across all archives in the data store per sample per minute. You can choose the time scales by clicking on the time options provided on the top right area of the screen. To scale the panel, click the icon. Receive Rate This panel gives you the trend of the recent rate at which the samples have been received per minute. You can choose the time scales by clicking on the time options provided on the top right area of the screen. To scale the panel, click the icon. |
| 6 | Collectors | This panel displays the details of all the unhealthy collectors connected to the system. To view the details of a particular collector, click the Details button. The Collector Detail Diagnostics dialog appears. To view all the collectors in the system click the Show All Collectors button. The Configuration Page appears. For more information on the collector panel, refer to the Collector Statistics topic. |
| 7 | Clients | This panels displays the client statistics of the top five read and write clients in the order of the load that they impose on the server. For more information, refer to the Client Statistics topic. |
| 8 | Color codes | The Error, Warning, and Information color codes are displayed based on the status of the Data Node, Collectors or Clients. |
Client Panel
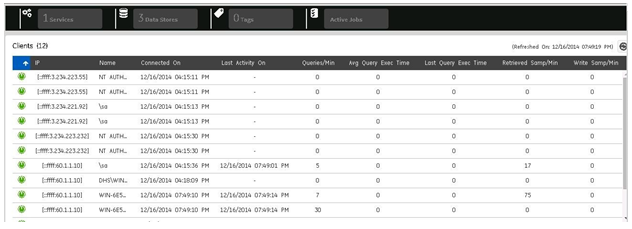
Client Statistics
The Client Statistics panel displays data described in the following table:
| Field | Description |
|---|---|
| Connection | Indicates the status of the current connection. |
| Machine Name | The host name from where the client is connected. |
| Log-In User Name | The user name with which the client is connected. |
| Connected On | The date and time when the connection was established. |
| Last Activity | On The time when the last read and write request was made. |
| Queries/Min | The current rate at which the query requests are made. |
| Average Query Execution Time | The average time taken to execute a query. |
| Timed Out Reads | The number of timed out read requests made by clients. This counter increments when a query made by a client is taking longer time than "Max Query Time" or returning more samples than specified in the "Max Query Intervals". |
| Samples Written/Min | The current rate at which the data samples are written. |
| Details | Click this button to view more client details. To view all the clients, click the Show All Clients button. The All Clients page appears |
Client Details

| Field | Description |
|---|---|
| Named Client/IP | The name of the client or IP address from where the client is connected. |
| Last Query Exec Time | The time taken to execute the last query. |
| Retrieved Samples/Min | The current rate at which the data samples are received. For more information, refer to the Client Statistics topic. |
Collector Panel
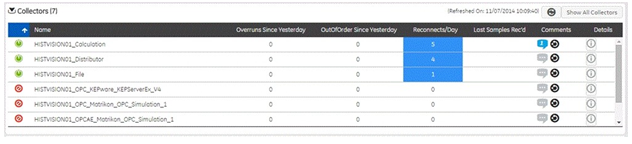
The Collector panel in the Dashboard shows details of all the collectors whose performance does not meet the required performance status. The collector statistics panel displays data described in the following table. Click the Show All Collectors button to view all the collectors connected to the system. The View All Collectors page is displayed.
| Field | Description |
|---|---|
| Connection | Indicates the status of the current connection. "Running" (Green) indicates that the collector is operating. "Stopped" (Red) indicates that it is in pause mode and not collecting data. "Unknown" indicates that status information about the collector is unavailable at present, perhaps as a result of a lost connection between collector and server. |
| Name | The name of the computer the collector is running on. |
| Overruns Since Yesterday | The overruns in relation to the total events collected for the past 24 hours. This value is calculated by using the following equation: OVERRUN_PCT = OVERRUNS / ( OVERRUNS + TOTAL_EVENTS_COLLECTED ). Overruns are a count of the total number of data events not collected on their scheduled polling cycle. In normal operation, this value should be zero. You may be able to reduce the number of overruns on the collector by increasing the tag collection intervals (per tag). |
| Out of Order Since Yesterday | The number of samples within a series of timestamped data values normally transmitted in sequence have been received out of sequence for the past 24 hours. This field applies to all collectors. Even though events are still stored, a steadily increasing number of out of order events indicates a problem with data transmission that you should investigate. For instance, a steadily increasing number of out of order events when you are using the OPC Collector means that there is an out of order between OPC Server and the OPC Collector. This may also cause an out of order between the OPC Collector and the Data Archiver, but that is not what this statistic indicates. |
| Reconnects/Day | Displays the number of reconnections that happened in the last 24 hours. |
| Last Samples Received | Displays the delayed data sample duration. |
| Comments | Displays the comments if any. |
| Details | Click this button to view the Collector Detail Diagnostics |
Collector Detail
Selecting the Details option for a particular collector pops up a display that shows the current statistics on the operation of that selected data collector.
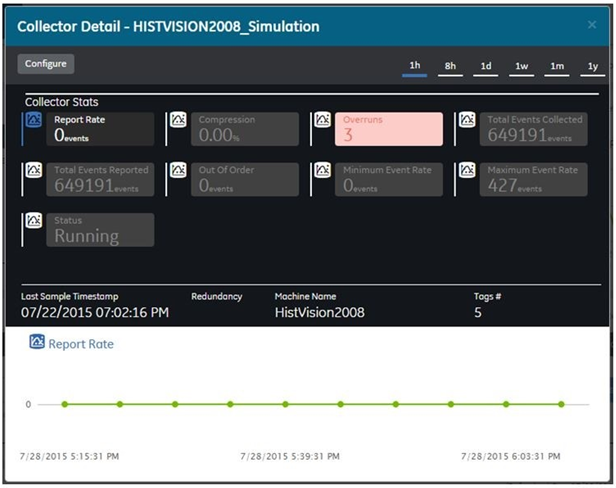
To view or modify the configuration details of the collector, click the Configure button. The statistics displayed on this screen are computed independently on various time scales and schedules. As a result, they may update at different times. You can choose the time scales by clicking on the time options provided on the top right area of the screen.
The collector detail diagnostics screen has the following types of fields.
- Trendable Fields
- These fields can be trended.
- These fields can be distinguished by the trend icon next to the field name.
- To graphically view a particular trendable field based on the timestamp, click on the field name.
- Non-Trendable Fields
- These fields cannot be trended.
- These fields have no trend icon next to the field name.
| Field | Description |
|---|---|
| Report Rate | This display is a trend chart that displays the average rate at which data is coming into the server from the selected collector. This is a general indicator of load on the Historian collector. Since this chart displays a slow trend of compressed data, it may not always match the instantaneous value of Report Rate displayed in the Collector panel of the System Statistics screen. |
| Compression | This display is a trend chart that displays the effectiveness of collector compression. If the chart displays a low current value, you can widen the compression deadbands to pass fewer values and increase the effect of compression. |
| Overruns Percent | This trend chart displays the value at which data overruns are occurring. This value is calculated by the following equation: OVERRUN_PCT =OVERRUNS / ( OVERRUNS + TOTAL_EVENTS_COLLECTED ) Overruns are a count of the total number of data events not collected. Under normal conditions, the current value should always be zero. If the current value is not zero, which indicates that data is being lost, you should take steps to reduce peak load on the system, by increasing the collection interval. |
| Total Events Collected | Counts the total number of events collected from the data source by the collector. |
| Total Events Reported | Counts the total number of events reported to the Historian archive from the collector. This number may not match the Total Events Collected field due to collector compression.. |
| Out of Order | The number of samples within a series of timestamped data values normally transmitted in sequence have been received out of sequence since collector startup. This field applies to all collectors. Even though events are still stored, a steadily increasing number of out of order events indicates a problem with data transmission that you should investigate. For instance, a steadily increasing number of out of order events when you are using the OPC Collector means that there is an out of order between the OPC Server and the OPC Collector. This may also cause an out of order between the OPC Collector and the data archiver but that is not what this statistic indicates. |
| Minimum Event Rate | Specifies the minimum number of data samples per minute sent to the archiver from all sources. |
| Maximum Event Rate | Specifies the maximum number of data samples per minute sent to the archiver from all sources. |
| Status | The current status of collection. "Running" indicates that the collector is operating. "Stopped" indicates that it is in pause mode and not collecting data. "Unknown" indicates that status information about the collector is unavailable at present, perhaps as a result of a lost connection between collector and server |
| Field | Description |
|---|---|
| Last Sample Timestamp | Displays when the last data sample was written. |
| Redundancy | Indicates whether collector redundancy is enabled or disabled. |
| Machine Name | Displays the machine name where the collector is running. |
| Tag# | Displays the number of tags added to the collector. |
Data Node Panel
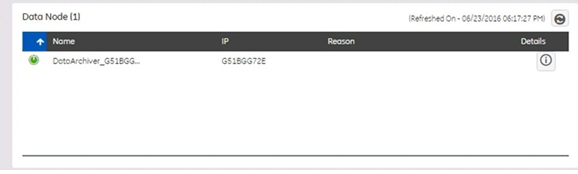
The Data Node panel displays data as described in the following table:
| Field | Description |
|---|---|
| Connection | Indicates the status of the current connection. "Running" (Green) indicates that the Data Archiver is active. "Stopped" (Red) indicates that the Data Archiver is inactive. "Pause" indicates that the user has manually paused it. |
| Name | The logical name of the service. |
| IP | The IP address or the host name of the service. |
| Reason | Displays why the Data Node is not performing as expected. The reason is a warning message for the disk running out of space or memory. To view the details of the problem, move the mouse over the reason. |
| Details | Click this button to view the Data Node Detail Diagnostics. |
Data Node Detail Diagnostics
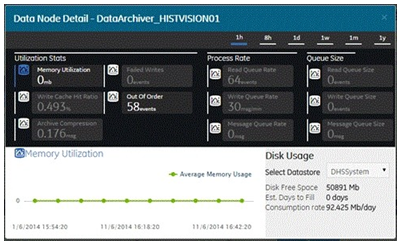
You can choose the time scales by clicking on the time options provided on the top right area of the screen. To graphically view a particular parameter based on the timestamp, click the chart icon of the parameter. Select the Datastore available with the selected data node to view its disk free space and its statistics.
| Field | Description |
|---|---|
| Memory Utilization | Indicates how much server memory is being consumed. |
| Write Cache Hit Ratio | The hit ratio of the write cache in percent of total writes. It is a measure of how efficiently the system is collecting data and should typically range from 95 to 99.99%. If the data is changing rapidly over a wide range, however, the hit percentage drops significantly because current values differ from recently cached values. More regular sampling may increase the hit percentage. Out of order data also reduces the hit ratio. |
| Archive Compression | The current effect of archive data compression. If the value is zero, it indicates that archive compression is either ineffective or turned off. To increase the effect of data compression, increase the value of archive compression deadbands on individual tags in the Tag Maintenance screen to activate compression. In computing the effect of archive compression, Historian counts internal system tags as well as data source tags. Therefore, when working with a very small number of tags and with compression disabled on data source tags, this field may indicate a value other than zero. If you use a realistic number of tags, however, system tags will constitute a very small percentage of total tags and will therefore not cause a significant error in computing the effect of archive compression on the total system. |
| Failed Writes | The number of samples that failed to be written. Since failed writes are a measure of system malfunctions or an indication of offline archive problems, the value shown in the display should be zero. If you observe a non-zero value, investigate the cause of the problem and take corrective action. The Historian also generates a message if a write fails. Note that the message only appears once per tag, for a succession of failed writes associated with that tag. For example, if the number displayed in this field is 20, but they all pertain to one Historian tag, you will only receive one message until the Historian tag is healthy again. |
| Out of Order | The number of samples within a series of timestamped data values normally transmitted in sequence have been received out of sequence since collector startup. This field applies to all collectors. Even though events are still stored, a steadily increasing number of out of order events indicates a problem with data transmission that you should investigate. For example, a steadily increasing number of out of order events when you are using the OPC Collector means that there is an out of order between the OPC Server and the OPC Collector. This may also cause an out of order between the OPC Collector and the data archiver but that is not what this statistic indicates. |
| Field | Description |
|---|---|
| Read Queue Rate | Specifies the number of read requests processed per minute, that came into the archiver from all clients. A read request can return multiple data samples. |
| Write Queue Rate | Specifies the number of write requests processed per minute, that came into the archiver from all clients. A write request can contain multiple data samples. |
| Message Queue Rate | Specifies the number of messages processed per minute. |
| Field | Description |
|---|---|
| Read Queue Size | Displays the total number of messages present in the Read queue. |
| Write Queue Size | Displays the total number of messages present in the Write queue. |
| Message Queue Size | Displays the total number of messages present in the Message queue. |
| Field | Description |
|---|---|
| Disk Free Space | The amount of disk space (in MB) left in the current archive. |
| Est. Days to Fill |
The amount of time left before the archive is full, based on the current consumption rate. At that point, a new archive must be opened (could be automatic). To increase the days to full, you must reduce the Consumption Rate as noted above. To ensure that collection is not interrupted, you should make sure that the Automatically Create Archives option is enabled in the Data Store Maintenance screen (Global Options tab). You may also want to enable Overwrite Old Archives if you have limited disk capacity. Enabling overwrite, however, means that some old data will be lost when new data overwrites the data in the oldest online archive. Use this feature only when necessary. The Estimated Days Until Full field is dynamically calculated by the server and becomes more accurate as an archive gets closer to completion. This number is only an estimate and will vary based on a number of factors, including the current compression effectiveness. The System sends messages notifying you at 5, 3, and 1 days until full. |
| Consumption Rate | The speed at which you are using up archive disk space. If the value is too high, you can reduce it by slowing the poll rate on selected tags or data points or by increasing the filtering on the data (widening the compression deadband to increase compression). |
Configuration Panel

| Field | Description |
|---|---|
| Services | Displays the number of services running. For more information, refer to the Configure Services section. |
| Data Stores | Displays the number of data stores configured in the system. For more information, refer to the Data Stores section. |
| Tags | The number of tags available with the data archiver. For more information, refer to the Tags section. |
| Active Jobs | Displays the number of current active jobs in the system. For more information, refer to the Jobs Page section. |
| Collectors | Displays the details of all the collectors available. For configuration of Collectors, refer to the Configure Collectors section. |
| Clients | Displays the details of all the clients present in the system. For more information, refer to the Clients section. |
Configure Collectors
| Field | Description |
|---|---|
| Connection | Indicates the status of the current connection. "Running" indicates that the collector is operating. "Stopped" indicates that it is in pause mode and not collecting data. "Unknown" indicates that status information about the collector is unavailable at present, perhaps as a result of a lost connection between the collector and server. |
| Name | The collector ID, which is used to identify the collector in an Historian system. |
| Rate | The current rate in number of samples/minute at which the server is receiving data from the collector. It is a measure of the collection rate and also of data compression activity. A value equal to the data acquisition rate, when Collector Compression Percent is zero, indicates that every data value received from the data source is being reported to the server. This means that the collector is not performing any data compression. You can lower the report rate, and make the system more efficient, by increasing the data compression at the collector. To do this, widen the collection compression deadbands for selected tags. |
| Overruns | The overruns in relation to the total events collected since startup. This value is calculated by using the following equation: OVERRUN_PCT = OVERRUNS / ( OVERRUNS + TOTAL_EVENTS_COLLECTED ) Overruns are a count of the total number of data events not collected on their scheduled polling cycle. In a normal operation, this value should be zero. You may be able to reduce the number of overruns on the collector by increasing the tag collection intervals (per tag). |
| Out of Order | The number of samples within a series of timestamped data values normally transmitted in sequence that have been received out of sequence since collector startup. This field applies to all collectors. Even though events are still stored, a steadily increasing number of out of order events indicates a problem with data transmission that you should investigate. For example, a steadily increasing number of out of order events when you are using the OPC Collector means that there is an out of order between the OPC Server and the OPC Collector. This may also cause an out of order between the OPC Collector and the data archiver but that is not what this statistic indicates. |
| Events Collected | Counts the total number of events collected from the data source by the collector. |
| Events Reported | Counts the total number of events reported to the Historian archive from the collector. This number may not match the Total Events Collected field due to collector compression. |
| Last Change | The timestamp when the last collection happened. |
| Redundancy | Displays the current redundancy status of the collector. "Active" state indicates that the collector is currently collecting data and "Standby" indicates that the collector is the standby for the primary collector. Note: This status will be displayed only when the Redundant Collector property of the collector is Enabled.
|
| Details | Click this button to view the Collector Detail Diagnostics. . |
| View/Edit | Click this button to examine or modify configuration parameters for any collector in your system. For more information, refer Collector Details Page. |
Configure Clients
Data Stores Page
The Data Store Information page lets you read, add, rename, and delete the data stores. To view the Data Stores, click the Configuration link, and then click the Data Stores link. The Data Stores page appears and displays the list of available data stores and their details. For more information, refer to the Configure Data Stores section.
| Field | Description |
|---|---|
| Data Store Name | Displays the name of the data store. |
| Type | Indicates whether the storage type is Historical or SCADA buffer. |
| Description | Displays the description of the data store. |
| Is Default | Indicates whether the data store is the default store. Select Yes if you want to set the data store as the default data store. |
| Number of Tags | Displays the number of tags the data store contains. |
| State | The state that the data store is in. The data store state is always running until you delete the data store. |
| Edit | Click this button to edit the data store configuration. |
| Delete | Click this button to delete the data store. |
| Details | Click this button to view the archive details of the data store. |
Jobs Page
When you add a mirror node, replicate a node, re-synch an archive file, back up an archive file or restore an archive file then a job is initiated with a Job ID, which will be seen on the user interface of the Historian Web Admin Console.
| Field | Description |
|---|---|
| Status | Displays the current status of the job (Succeeded, Failed and In Progress) in different color codes. If you see a Failed job, you can expand it to see the description of the failure. |
| Job ID | The unique ID given to a particular job. |
| Type | The type of job. |
| Description | The description of the job. |
| Percentage | The percentage of completion of the job. |
| Start Time | The time at which the job started. |
| Complete Time | The time at which the job was completed. |
Services Page
The Services page displays all the services running in the system. You can also add a mirror node from the Services page. To refresh the services page, click the ![]() Refresh icon.
Refresh icon.
- Client Manager
- Configuration Manager
- Data Archiver
- Diagnostic Manager
Service Configuration
The Service Configuration page displays data for each service.
| Field | Description |
|---|---|
| Computer Name | The name of the computer the service is currently running. |
| Service Name | The name of the service and its current status. |
| Port | The port number. |
| Type | The type of the node service. |
Editing a Service
Tags Page
To display the Tags page, click the Tags link in any of the Collectors, Clients, or Configuration page. The Tags page lets you read and modify all tag parameters of the Historian system. To access information on a specific tag or group of tags, however, you must first search for the tags.
You can search for tags in the Historian Tag Database by clicking the Search button or the Advanced Search button. You can also add tags manually or from the collector by clicking the appropriate icons on the Tags page.
The Tags page has two sections: Tag Viewer and Tag Editor.
Tag Viewer
Displays all the tags available in the system. You can choose to display the total number of tags you want to view by selecting the Show entries. To view all the tags, click the page numbers available at the bottom right of the section.
- Add Tag
- Delete Tag
- Rename Tag
- Search for Tags
- Filtering Tags
- Copy Tag
- Display a Tag
Tag Editor
In this section, you can view and edit specific tag parameters and options. To view all the tags, click the page numbers available at the bottom right of the section.
The Tag Editor allows you to edit specific tag parameters and options for one or more selected tags. To modify the values, enter new values in the appropriate fields and then click the Update button at the bottom of the screen to apply the changes. The Update button, when clicked, applies all parameter changes you have made on any tabs in this screen. If you want to cancel changes and return to the original values or settings, open a different page and then return to the Tag Details screen without clicking the Update button. For more information, refer to the following sections.
Advanced Tab
| Field | Description |
|---|---|
| Time Assigned By | The source of the timestamp for a data value is either the collector or the data source. All tags, by default, have their time assigned by the collector. When you configure a tag for a polled collection rate, the tag is updated based on the collection interval. For example, if you set the collection interval to 5 seconds with no compression, then the archive is updated with a new data point and timestamp every 5 seconds, even if the value isn't changing. However, if you change the Time Assigned By field to Source for the same tag, the archive updates only when the device timestamp changes. For example, if the poll time is still 5 seconds, but the timestamp on the device does not change for 10 minutes, no new data is added to the archive for 10 minutes. Note: This field is disabled for Calculation and Server-to-Server tags.
|
| Time Zone Bias | The number of minutes from GMT that should be used to translate timestamps when retrieving data from this tag. For example, the time zone bias for Eastern Standard time is -300 minutes (GMT-5). This property is not used during collection. Use this option if a particular tag requires a time zone adjustment during retrieval other than the client or server time zone. For example, you can retrieve data for two tags with different time zones by using the tag time zone selection in the iFIX chart. |
| Time Adjustment | If the Server-to-Server Collector is not running on the source computer, select the Adjust for Source Time Difference option if you want to compensate for the time difference between the source archiver computer and the collector computer. The Time Adjustment field applies only to Server-to-Server tags that use a polled collection type |
| Data Store | Displays the Data Store the tag belongs to. |
Collection Tab
| Field | Description |
|---|---|
| Collector | The name of the collector for the selected tag. Click the drop-down arrow to display a list of all collectors. |
| Source Address | The address for the selected tag in the data source. Click the Browse button (...) to display a browse window. Leave the Source Address field blank for Calculation and Server-to-Server tags. Note: When exporting or importing tags using the EXCEL Add-In, the Calculation column, not the SourceAddress column, holds the formulas for the Calculation or Server-to-Server tags.
|
| Data Type | A list of data types. Note: If you change the data type of an existing tag between a numeric and a string or binary data type (and vice versa), the tag's compression and scaling settings will be lost.
|
| Data Length | The number of bytes for a fixed string data type. This field is active only for fixed string data types. This field is adjacent to the Data Type field. |
| Enumerated Set Name | The name of the Enumerated Set that can be assigned to the tags. Click the Browse button (...) to display the Define Enumerated Set window. |
| Is Array Tag | Indicates the tag is an array tag. |
| Calc Type | Indicates the type of tag. Analytic Tag, Raw tag or Expression Tag. |
Choosing a Data Type
The main use of the scaled data type is to save space. Instead of using 4 bytes of data, it uses only 2 bytes. The scaled data type accomplishes this by storing the data as a percentage of the EGU limit. This saving of space results in a loss of precision. Because of the way that the scaled data type stores data, changing of the EGU limits will result in a change in the values that are displayed. For example, if the original EGU values were 0 to 100 and a value of 20 was stored using the scaled data type and if the EGUs are changed to 0 to 200 at a later date, that value of 20 will be represented as 40.
| Field | Description |
|---|---|
| Collection | Select the appropriate option to enable or disable collection for this tag. The default setting is Enabled. If you disable collection for the tag, Historian stops collecting data for the tag, but does not delete the tag or any data. |
| Collection Type | Select the type of data collection used for this tag, which can be polled or unsolicited. Polled means that the data collector requests data from the data source at the collection interval specified in the polling schedule. Unsolicited means that the data source sends data to the collector whenever necessary (independent of the data collector polling schedule). |
| Collection Interval | Enter the time interval between readings of data from this tag. With Unsolicited Collection Type, this field defines the minimum interval at which unsolicited data will be sent by the data source. |
| Collection Offset | Used with the collection interval to schedule collection of data from a tag. Note: The minimum value you can enter in this field is 1000 ms. If you enter a value in milliseconds, note that the value must be in intervals of 1000 ms. For example, 1000, 2000, and 3000 ms are valid values, but 500 and 1500 ms are invalid values. For example, if you want to collect a value for a tag every hour at thirty minutes past the hour (12:30, 1:30, 2:30, and so on), you would enter a collection interval of 1 hour and an offset of 30 minutes. As another example, if you want to collect a value each day at 8am, you would enter a collection interval of 1 day and an offset of 8 hours.
|
| Time Resolution | Select the precision for timestamps, which can be either seconds, milliseconds or microseconds. |
Condition-Based Collection
Condition-based collection can be used to archive only the specific data that is required for analysis, rather than archiving data at all times, as the collector is running. For example, if a collector has tags for multiple pieces of equipment, you can stop collection of tags for one piece of equipment during its maintenance.
It is typically used on tags that use fast polled collection but you don't want to use collector compression. While the equipment is running, you want all the data but when the equipment is stopped, you don't want any data stored. The trigger tag will also typically use polled collection. But, either tag could use unsolicited collection.
The condition is evaluated every time data is collected for the data tag. When a data sample is collected, the condition is evaluated and data is either queued for sending to the archiver, or discarded. If the condition cannot be evaluated as true or false (for example, if the trigger tag contains a bad data quality or the collector is not collecting the trigger tag), the condition is considered true and the data is queued for sending.
No specific processing occurs when the condition becomes true or false. If the condition becomes true, no sample is stored to the data tag using that condition, but the data tag will store a sample the next time it collects. When the condition becomes false, no end of the collection marker is stored until the data tag is collected. For example, if the condition becomes false at 1:15 and the data tag gets collected at 1:20, the end of collection marker is created at 1:20 and has a timestamp of 1:20, not 1:15.
This condition-based collection is applicable only to the following collectors:
- Simulation Collector
- OPC Collector
- IFIX Collector
- PI Collector
| Field | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Condition Based | Select the appropriate option to enable or disable condition-based collection for a tag. The default setting is Disabled. | ||||||||||||
| Trigger Tag | The name of the tag used in the condition. Use the browse button to select a trigger tag from the list of tags associated with the collector. | ||||||||||||
| Comparison | Select the appropriate comparison operator from the drop-down list. The following is a list of comparison operator parameters:
|
||||||||||||
| Compare Value | Enter an appropriate target value which is compared against the value of the triggered tag. Make sure while using '=' and '!=' comparison parameters, that the format of the compared value and triggered tag are similar. For example, for a float type trigger tag, the compare value must be a float value; otherwise, the condition result is an invalid configuration, condition-based collection is disabled, and all the data is sent to the archiver. | ||||||||||||
| End of Collection Markers | Select the appropriate option to enable or disable end of collection markers. The default setting is enabled. When the condition becomes false, all the tags values are marked as "Bad", and subquality as "ConditionCollectionHalted." Trending and reporting applications can use this information to indicate that the real-world value is unknown after this time until the condition becomes true and a new sample is collected. If disabled, a bad data marker is not inserted when the condition becomes false. |
Compression Tab
| Field | Description |
|---|---|
| Collector Compression (Enabled, Disabled) | Select the appropriate option to enable or disable compression at the collector level. Collector compression applies a smoothing filter to incoming data by ignoring incremental changes in values that fall within a deadband centered on the last reported value. The collector reports any new value that falls outside the deadband to the Historian archive and then centers the deadband on the new value. |
| Collector Deadband | The current value of the compression deadband. This value can be computed as a percentage of the span, centered on the data value or given as an absolute range around the data value. Note: With some OPC Servers, the whole deadband value is added to and subtracted from the last data value. This effectively doubles the magnitude of the deadband compared to other OPC Servers.
|
| Engineering Unit | Converts the deadband percentage into engineering units and displays the result. This value establishes the deadband range that is centered around the new value. When enabling Archive Compression or Collector Compression, the Engineering Units field represents a calculated number created to give an idea of how large a deadband you are creating in Engineering Units. The deadband is entered in percent (%) and Historian multiplies that percent by the range (Hi Engineering Units-Lo Engineering Units) to calculate the percentage in Engineering Units. |
| Collector Compression Timeout | Indicates the maximum length of time the collector will wait between sending samples for a tag to the archiver. This time is kept per tag, as different tags report to the archiver at different times. For polled tags, the Collector Compression Timeout value should be in multiples of your collection interval. After the timeout value is exceeded, the tag stores a value at the next scheduled collection interval, and not when the timeout occurred. For example, if you have a 10 second collection interval, a 1 minute compression timeout, and a collection that started at 2:14:00, then if the value has not changed, the value is logged at 2:15:10 and not at 2:15:00. For unsolicited tags, a value is guaranteed in, at most, twice the compression timeout interval. A non-changing value is logged on each compression timeout. For example, an unsolicited tag with a 1 second collection interval and a 30 second compression timeout is stored every 30 seconds. A changing value for the same tag may have up to 60 seconds between raw samples. In this case, if the value changes after 10 seconds, then that value is stored, but the value at 30 seconds (if unchanged) will not be stored. The value at 60 seconds will be stored. This leaves a gap of 50 seconds between raw samples which is less than 60 seconds. Compression timeout is supported in all collectors except the PI collector. |
| Archive Compression (Enabled, Disabled) | Select the appropriate option to enable or disable compression at the Historian archive level. If enabled, Historian applies the archive deadband settings against all reported data from the collector. |
| Archive Deadband | The current value of the archive deadband expressed as a percent of span or an absolute number. Each time the system reports a new value, it computes a line between this data point and the last archived value. The deadband is calculated as a tolerance centered about the slope of this line. When the next data point is reported, the line between the new point and the last archived point is tested to see if it falls within the deadband tolerance calculated for the previous point. If the new point passes the test, it is reported and is not archived. This process repeats with subsequent points. When a value fails the tolerance test, the last reported point is archived and the system computes a line between the new value and the newly archived point, and the process continues. |
| Engineering Unit | Converts the deadband percentage into engineering units and displays the result. This value establishes the deadband range that is centered on the new value. When enabling Archive Compression or Collector Compression, the Engineering Units field represents a calculated number created to give an idea of how large a deadband you are creating in Engineering Units. The deadband is entered in percent (%) and Historian multiplies that percentage by the range (Hi Engineering Units-Lo Engineering Units) to calculate the percentage in Engineering Units. |
| Archive Compression Timeout | Indicates the maximum length of time from the last stored point before another point is stored, if the value does not exceed the archive compression deadband. The data archiver treats the incoming sample after the timeout occurs as if it exceeded compression. It then stores the pending sample. For more information on Collector and Archive Corruption, refer to the Notes on Collector and Archive Compression topic. |
To determine how your specific server handles deadband, refer to the documentation of your OPC Server. Example: The engineering units are 0 to 200. The deadband value is 10%, which equals 20 units. If the deadband value is 10% and the last reported value is 50, the value will be reported when the current value exceeds 50 + 10 = 60 or is less than 50-10 = 40. Note that the deadband (20 units) is split around the last data value (10 on either side.) Alternatively, you could specify an absolute deadband of 5. In this instance, if the last value was 50, a new data sample will be reported when the current value exceeds 55 or drops below 45. If compression is enabled and the deadband is set to zero, the collector ignores data values that do not change and records any that do change. If you set the deadband to a non-zero value, the collector records any value that lies outside the deadband. If the value changes drastically, a pre-spike point may be inserted. See the Spike Logic section for more details.
Understand Collector and Archive Compression
This section describes the behavior of collector and archive compression. Understanding these two Historian features will help you apply them appropriately to reduce the storage of unnecessary data. Smaller archives are easier to maintain and allow you to keep a greater time span of historical data online.
Collector compression applies a smoothing filter, inside the collector, to data retrieved from the data source. By ignoring small changes in values that fall within a deadband centered on the last reported value, only significant changes are reported to the archiver. Fewer samples reported, yields less work for the archiver and less archive storage space used. The definition of significant changes is determined by the user by setting the collector compression deadband value.
For convenience, the Historian Web Admin Console calculates and shows the deadband in engineering units if you enter a deadband percentage. If you later change the high and low EGU limits, the deadband is still a percentage, but of the new limits. A 20% deadband on 0 to 500 EGU span is 100 engineering units. If you change the limits to 100 and 200, then the 20% is now 20 engineering units.
The deadband is centered on the last reported sample, not simply added to it or subtracted. If your intent is to have a deadband of 1 unit between reported samples, you need a compression deadband of 2, so that it is one to each side of the last reported sample. In an example of 0 to 500 EGU range, with a deadband of 20%, the deadband is 100 units, and the value has to change by more than 50 units from the last reported value.
Changes in data quality from good to bad, or bad to good, automatically exceed collector compression and are reported to the archiver. Any data to that comes to the collector out of time order will also automatically exceed collector compression.
It is possible for collected tags with no compression to appear in Historian as if the collector or archive compression options are enabled. If collector compression occurs, you will notice an increase in the percentage of the Compression value from 0% in the Collectors panel of the System Statistics screen in the Historian Administrator. When archive compression occurs, you will notice the Archive Compression value and status bar change on the System Statistics screen.
For all collectors, except the File Collector, you may observe collector compression occurring for your collected data (even though it is not enabled) if bad quality data samples appear in succession. When a succession of bad data quality samples appears, Historian collects only the first sample in the series. No new samples are collected until the data quality changes. Historian does not collect the redundant bad data quality samples, and this is reflected in the Collector Compression percentage statistic.
For a Calculation or Server-to-Server Collector, you may possibly observe collector compression (even though it is not enabled) when calculations fail, producing no results or bad quality data.
The effect of Collector Compression Timeout is to behave, for one poll cycle, as if the collector compression feature is not being used. The sample collected from the data source is sent to the archiver. Then the compression is turned back on, as configured, for the next poll cycle with new samples being compared to the value sent to the archiver.
Archive Compression
Archive compression can be used to reduce the number of samples stored when data values for a tag form a straight line in any direction. For a horizontal line (non-changing value), the behavior is similar to collector compression. But, in archive compression, it is not the values that are being compared to a deadband, but the slope of line those values produce when plotted against time.
Archive compression logic is executed in the data archiver and, therefore, can be applied to tags populated by methods other than collectors. Archive compression can be used on tags where data is being added to a tag by migration, or by the file collector, or by an SDK program for example.
Each time the archiver receives a new value for a tag, the archiver calculates a line between this incoming data point and the last archived value. The deadband is calculated as a tolerance centered about the slope of this line. The slope is tested to see if it falls within the deadband tolerance calculated for the previous point. If the new point does not exceed the tolerance, it is held by the archiver rather than being archived to disk. This process repeats with subsequent points. When an incoming value exceeds the tolerance, the value held by the archiver is written to disk and the incoming sample becomes held.
The effect of the archive compression timeout is that the incoming sample is automatically considered to have exceeded compression. The held sample is archived to disk and the incoming sample becomes the new held sample. If the Archive Compression value on the System Statistics screen indicates that archive compression is occurring, and you did not enable archive compression for the tags, the reason could be because of internal statistics tags with archive compression enabled.
General Tab
| Field | Description |
|---|---|
| Description | The tag description of the selected tag. |
| EGU Description | The engineering units, if any, assigned to the selected tag. Often referred to as Unit of Measure, or UoM. |
| Comment | Comments, if any, that apply to the selected tag. |
| StepValue | This tag property is used to indicate that the actual measured value changes in a sharp step instead of a smooth linear interpolation. This option should be selected only for numeric data. Enabling this option affects only data retrieval; it has no effect on data collection or storage |
| Spare Configuration | The Spare 1 through Spare 5 fields list any configuration information stored in these fields. |
Scaling Tab
| Field | Description |
|---|---|
| Hi Engineering Units | Displays the current value of the upper range limit of the span for this tag. |
| Lo Engineering Units | Displays the current value of the lower range limit of the span for this tag. |
| Field | Description |
|---|---|
| Input Scaling | Select the appropriate option to enable or disable input scaling, which converts an input data point to an engineering units value. |
| Hi Scale Value | The upper limit of the span of the input value. Lo Scale Value The lower limit of the span of the input value. |
OPC Servers and TRUE Values
Some OPC Servers return a TRUE value as -1. If your OPC Server is returning TRUE values as -1, modify the following Scaling tab settings in the Tag Maintenance screen of the Historian Administrator:Hi Engineering Units = 0
Lo Engineering Units = 1
Hi Scale Value = 0
Lo Scale Value = -1
Input Scaling = Enabled Data Mirroring
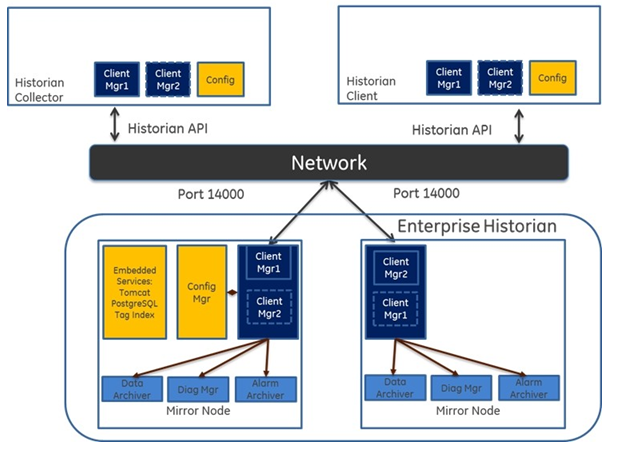
Historian provides mirroring of stored data on multiple nodes to provide high levels of data reliability. Data Mirroring also involves the simultaneous action of every insert, update and delete operations that occurs on any node. Data mirroring provides continuous data read and write functionality. The Enterprise Edition of Historian allows you to have up to 3 mirrors: a primary and two additional mirrors.
In a typical data mirroring scenario, one server acts as a primary server to which the clients connect. To create a mirror, you add mirror nodes and establish a data mirroring session relationship between the server instances. All communication goes through the Client Manager, and each Client Manager knows about the others. Mirrors must be set up in a single domain. You can add only 3 nodes in a mirrored environment.
Requirements for configuring Mirror Nodes
The hardware and software requirements for all the nodes should be identical. For more information on the Hardware and Software requirements, refer to the Getting Started Guide e-book. Mirrors must be set up in a single domain.
- Minimum 8GB RAM
- Dual Core Processor
- 64-Bit Operating System
- Tag Properties
- Tag Aliases
- Collectors
- Collector Properties
- Enumerated Sets
- Enumerated Set Properties
- Data Stores
- Tags of User Defined Types
- User Defined Type Tag Properties
- Services Properties
Mirror Node Setup